
Web scraping is the extraction of information from a website with or without the consent of the site owner. Most website scraping is done with malicious intent, but regardless of the purpose, several website scraping techniques are used. Among new and growing businesses, web crawling has become a household term, partly due to the idea that large-scale data collection is necessary to survive in the marketplace. Not all companies have what it takes to extract data through a web search, so they outsource the service to a reputable agency. We have listed the following web scraping best practices that you should follow.
10. Avoid Honeypots
“Honeypot” is an HTML link that is not visible to the user in the browser but is accessible by the web browser. One of the easiest ways to do this is to set the CSS selector to show none. If you try to retrieve data from a website by sending a request to one of these hidden links, the web server may detect activity that cannot be performed by a human end-user and block it. the scanner accordingly. An easy way to get around this is to use the selenium displayed function. Since Selenium renders the web page, it checks to see if the element is visible.
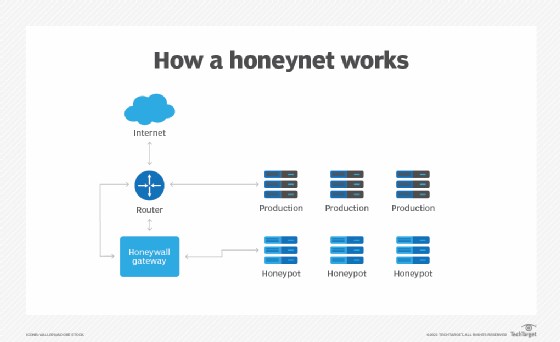
9. Selecting Objects On A Web Page
Depending on the tool you are using, there are several ways to select objects on a web page. If you’ve checked out the site you’re trying to find, you’re probably familiar with the structure of tags and how they interlock. In general, there are two main ways to select page objects, that is using CSS selectors or XPATH navigation.
8. Detect When You Have Been Blocked
Most sites don’t appreciate being removed. Some of them have developed anti-scratch methods and will block you. Usually, you’ll know right away that you’ve been blocked, as you’ll get a 403 error code. However, there are more malicious ways to block you without your knowledge. Some sites will still send you data, but it’s intentionally false. By logging in, you can monitor how the site responds and be alerted when something is out of the ordinary for example, a very short response time.
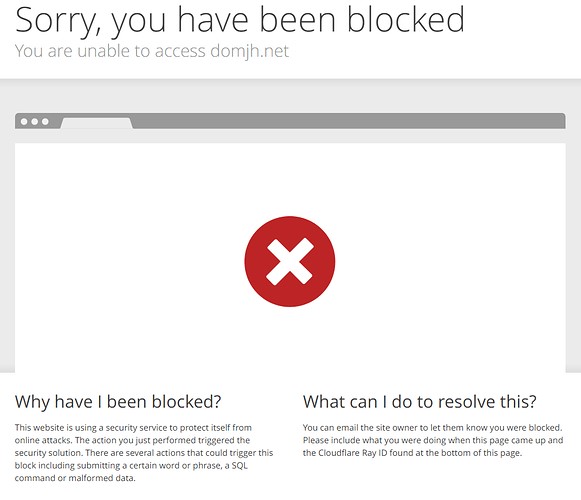
7. Cache To Avoid Unnecessary Requests
If there was a way to find out what pages your web browser has visited, then the scan time could be reduced. That is where caching comes in. You should cache HTTP requests and responses. Then you can write it to a file for a single thing, and if you need to do the scraping more than once, write it to the database. Page caching can help you avoid making unnecessary requests.
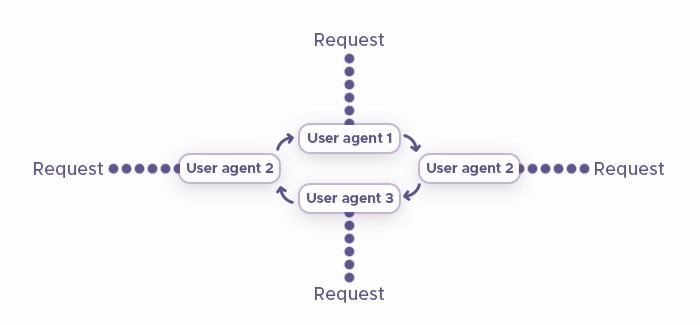
6. Web Scape While Rotating User Agents
We can do user agent rotation by manually changing the headers or by writing a function that rotates the user agent list every time we start the web search script. That can be done in the same way as the previous function for retrieving IP addresses. You can find many sites that can take different user agent strings.
5. Use Handless Browser
Many web pages have their content rendered in Javascript and therefore cannot be extracted directly from raw HTML. The only way you can do this is to use a headless browser. The headless browser will process the Javascript and display all the content. It is headless because there is no graphical user interface. That is an advanced way to simulate a human user, where the scraper accesses and parses the page as if using a regular browser.

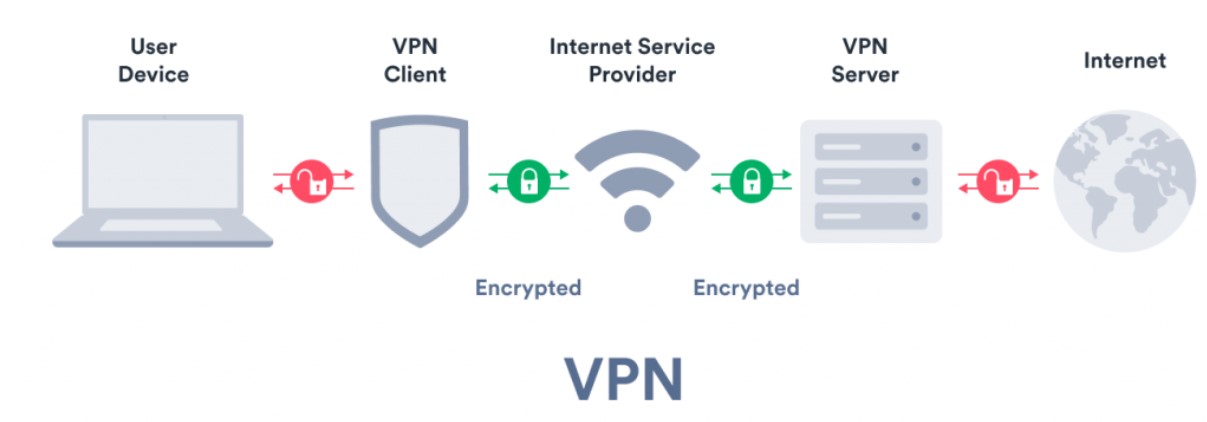
4. VPN
The VPN will change your original IP address to a new one and hide your IP address. It helps you access location-based content. VPNs are not made for a large-scale commercial use case to ensure the anonymity of an individual user. However – for a small-scale use case, a VPN is sufficient.
3. IP Address Rotation
If you want to know how to scan a website while using multiple IP addresses, look no further. You should start by using free proxies available on the web. However, keep in mind that because these proxies are free, many people use them, and therefore – they are slow and often fail because they have been blocked by the server or are overloaded. Therefore, use a private proxy whenever possible.

2. Don’t Follow The Same Crawling Pattern
Although users and robots use data from a website, there are inherent differences. Humans are slow and unpredictable, but bots are fast but predictable. Website anti-scraping technologies use this fact to block web scraping. So, it’s probably a good idea to incorporate some random action that confuses scratch-resistant tech.
1. Respect The Website And The Owner
Our first piece of advice is pretty common respect the site you’re scrapping. Read the robots.txt file written by the site owner to learn which pages you can or cannot scrape. It will also include information about how often you are allowed to scrape the site. In addition, you must respect other users accessing the site. That will cause a poor website experience for other users. That is courtesy of searching the web. If you do not follow these rules, you risk having your IP address blocked.





")

")








{kind=link}