
ELASTIC MAPREDUCE
Amazon Elastic Map Reduce is a web service that makes it effortless to development huge amounts of data resourcefully. Elastic Map Reduce uses Hadoop processing combined with several AWS services to do such tasks as web indexing, data mining, log file analysis, machine learning, scientific simulation, and data warehousing.
Amazon Elastic MapReduce use Amazon EC2 to create Hadoop cluster and use Amazon simple storage service (S3) to store data, script, log file, output result.
Elastic MapReduce takes care of provisioning an Amazon EC2 cluster, terminating it, moving the data between it and Amazon S3, and optimizing Hadoop. Elastic MapReduce removes most of the cumbersome details of setting up the hardware and networking required by the server cluster, such as monitoring the setup, configuring Hadoop, and executing the job flow. Together, Elastic MapReduce and Hadoop provide all of the power of Hadoop processing with the ease, low cost, scalability, and power of Amazon S3 and Amazon EC2.
Hadoop is a framework, which uses java software to implement huge data processing across a cluster of server. It is a free software. MapReduce is a programming model, which is use by Hadoop to divide dataset into small fragments. After this Hadoop, distribute a data fragment and copy of MapReduce executable to each node in Hadoop cluster. Each slave node runs the MapReduce executable on its subset of the data. Hadoop then combines the results from all of the nodes into a finished output.
MapReduce is a combination of mapper and reducer that work jointly to procedure data. Now check how it works.
First Amazon Map Reduce gives security to instance one for master node and another for core node and task node.
If dataset is huge then Hadoop divide data set into small Data set to process speedily on a single cluster node.
After completion of this MapReduce, executable to core and task node. Mapper function is that its use an algorithm which we supply as a key/value pair. And reducer function is that which collect all the result from all the mapper function in the cluster, remove redundant keys and perform operation on all the value in each key, then out put the result.
Hadoop contain three instance groups.
1) Master instance group.
2) Core instance group.
3) Task instance group.
1) Master instance group: the main task of master instance group is distribute executable to core instance group and task instance group and monitoring on it. In addition, check the instance is not scratch, failure each core and task node has a copy of Map reduce executable and receive a portion of complete data set from Amazon S3. Each node process data, complete work and given back to Amazon S3 and deliver status metadata to master node.
2) Core instance group: core instance group contain at least one core node and core node contain Hadoop Distributed File System (HDFC). ones a job flow is running we can increase core node but can’t decrease core node.
3) Task instance group: it is an option instance group. we can add it at starting or when job flow is running it and also remove it anytime. it’s not contain HDFC .and when the creation of task instance group its required at least one task node.
- In Elastic MapReduce each process is called a step and sequence of one or more steps is called a job flow. A job flow id is unique in all launched job flow. Step is a MapReduce Algorithm implemented on java Jar or Hadoop streaming program. Job flow is a sequence of steps. Moreover, one output of one-step is an input of another step. for example you need to count number of digit in textile i.e. first step and second is find maximum digit so the first step output is input of second step.
- Data transfer from one-step to another using file store in HDFC. Data store in this file up to job flow is running. We can specify a Map Reduce Algorithm using stream, Hive, Pig.
- Streaming is a process to create and run job flow using any executable program or script. We can program any function using a language C++, Ruby, PHP, pearl.
- Hive is an open source, data warehouse package .hive script use Hive QL-query language which is based on SQL which support where house data interaction. You can use hive 0.5 with Hadoop 0.18 or 0.20 by setting Hadoop version. Hive support iterative and batch type job flow.
- Pig is an Apache library written in a language called Pig Latin and used to convert those command into MapReduce job flow. Using Pig, you can create database types of queries and at a time, you can execute only one command. You can run Pig 0.6 with Hadoop .18 or 0.20. Pig support iterative and batch type job flow.
Completed, failed, running, shutting down, terminated, waiting are the state of job flow and pending, running, completed, cancelled, failed are the step state.
Create job flow with custom bootstrap action:
Step1) First sign up in Amazon Elastic Map Reduce. Signup page appear.
After the Billing system it will ask for to enter address or use your previous address which were you given at sign up AWS time?
Now After complete this next page will open it show that check selection and complete sign up.
In addition, select complete signup and after completion you can Use service of elastic Map Reduce.
Step 2) Start a new job flow:
Click on create new job flow.
Step 3) in the define Job page, give this information.
Enter name of your job flow here we give “techno Encyclopedia”. There are two options shown.

Run your own application i.e. using command line interface. If you select this option then in drop down menu appear like this. In this, choose your job type.
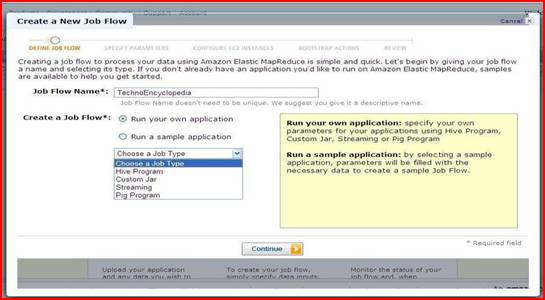
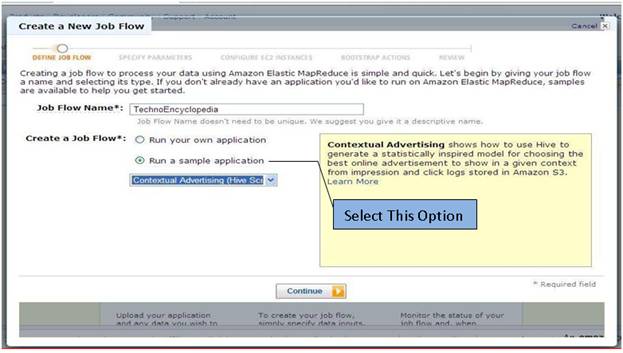
Secondly is a sample application. Here we select second option and from the dropdown menu select job flow.
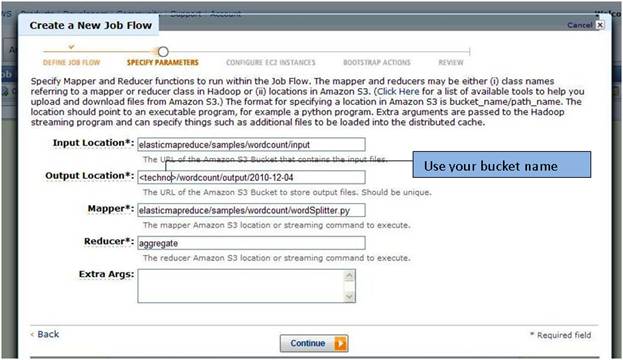
Step 4) In specify parameters page, replace the <your bucket> with the Amazon S3 valid bucket name from which data you want to apply job flow. Here we have given “techno” as bucket name. In addition, click continue.
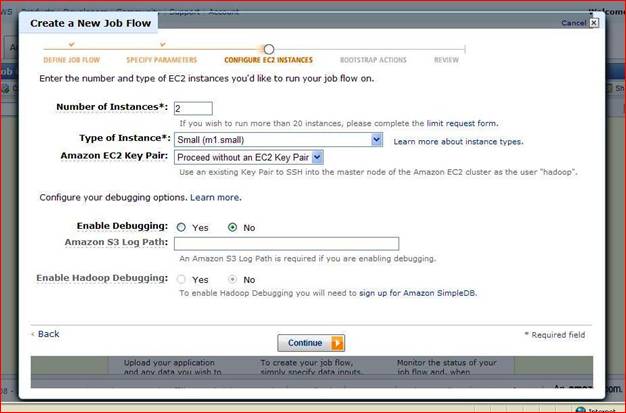
Step 5) On the Configure EC2 Instances page, accept the default parameters and click Continue.
Step 6) On the Bootstrap Actions page; select Configure your Bootstrap Actions. Then click continue.
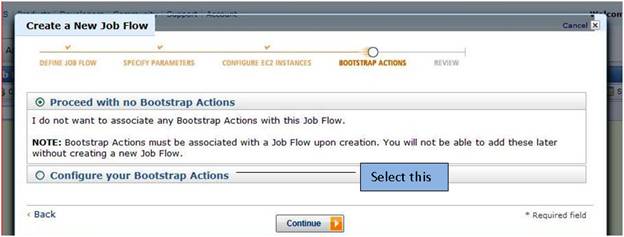
Next bootstrap action page will appear like this.
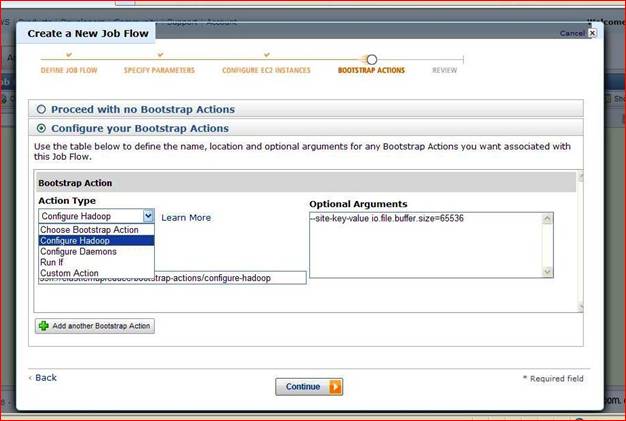
Here Choose your Action type and click continue. There are four Action type configure Hadoop; configure Daemons, Run If, and Custom Action. When you select action type, other parameter it will take automatically.
Step 7) On review page give information about job flow and if we want to change then click the edit button and change it or else click continue.
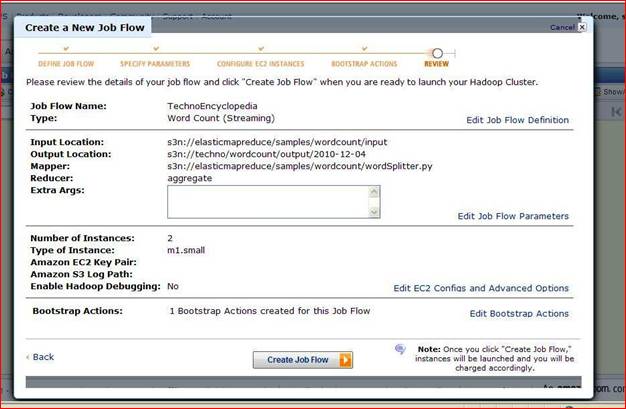
Step 8) if information correct click create job flow. And if error occurs correct it and select create job flow
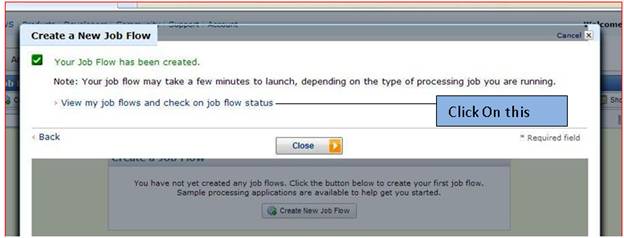
Step 9) Now it will show job flow as here we create “techno Encyclopedia”.
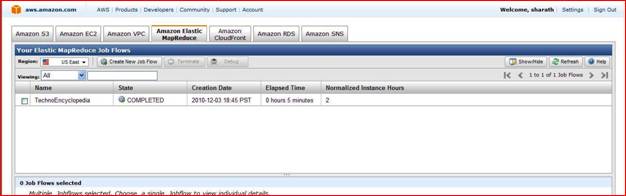
When you select job flow you will see its property, steps, Instance group etc.
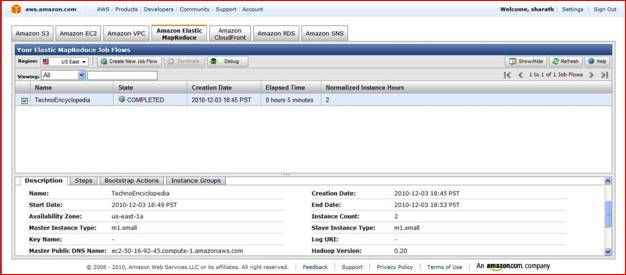
Second tab is step which shows information about job flow, start date, end date.
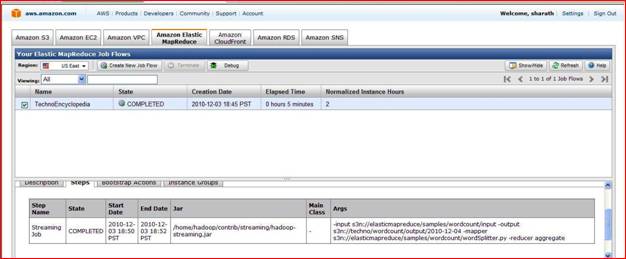
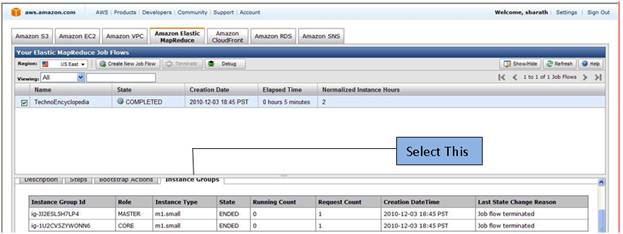
And if you want information about instance group then click on instance group.
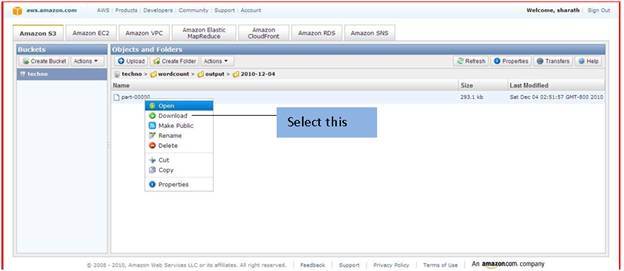
Now if you want to see your job flow result then go to Amazon S3 -> selects your bucket i.e. the bucket name you had given at time of creation of job flow.
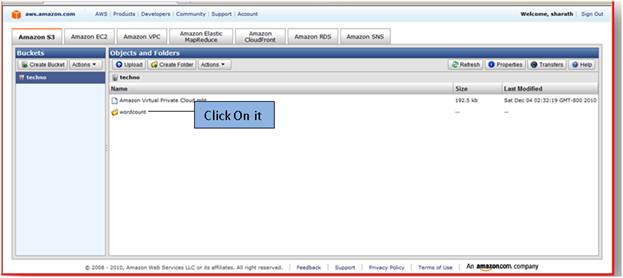
As you seen it one folder name is word count created by itself to store job flow result. Now click on it
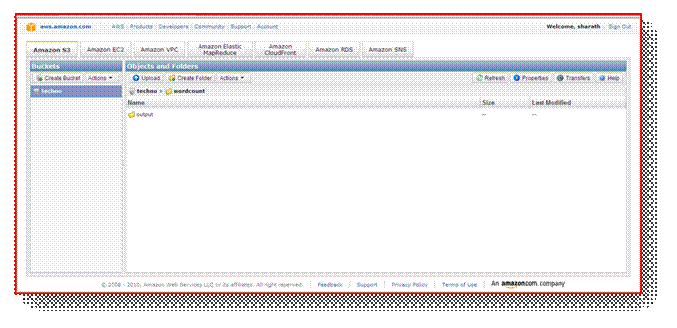
Now in word count folder output folder is created click on it will open like this.
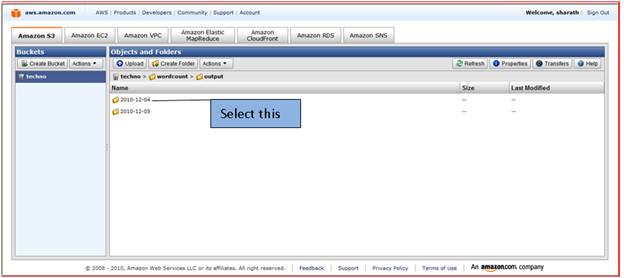
In that their show folders which have an output file result. Click on first on 2010-12-04. Note: it is not necessary same folder created according to your application folder name is given.
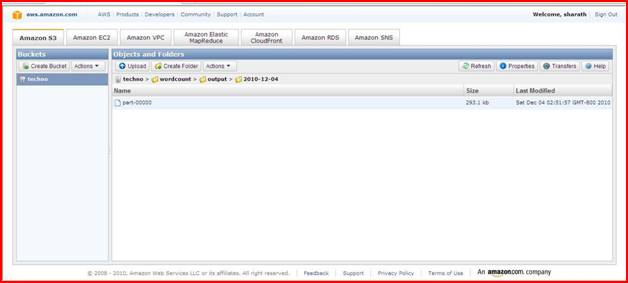
Here in our application part -0000 file created. Now download it and open it on pc it will display the output of job flow. As we created job flow the count the word occurs in text file. It will display occurrence of each word count number in ascending format.
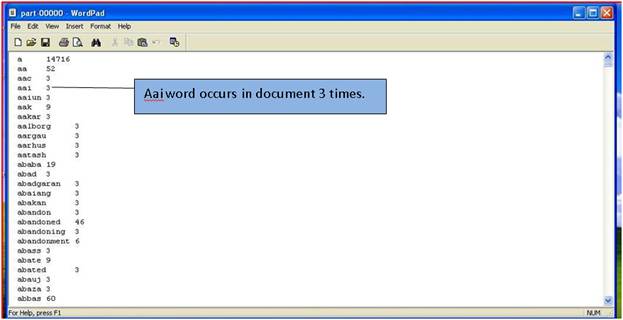
This is output file.
So in this way Elastic map reduce is useful to give result effectively and fast way. Similar to this you can create any job flow by your own or take default job flow.
- Feature of Elastic Map Reduce:
1. One of the features of Amazon elastic map reduce is bootstrap action. Bootstrap action is run a script on the Elastic map reduce cluster before the Hadoop start. It is store in Amazon S3 and when new job flow is start it is downloads from Amazon S3. There are two types of bootstrap action available. One is predefined bootstrap action include configure Hadoop, Daemons . Second is custom bootstrap in that you have to write action using language such as Python, Runy and Pearl. We can use bootstrap action from command line argument, from AWS management console, from Elastic Map Reduce API.
2. After completion of job flow data can be send to Amazon S3 using http Protocol. Elastic map reduce use a secure path to send data to Amazon S3 and we can encrypt data and send so
Data is more secure. In this Way Elastic MapReduce provide data security.
3. Ones a job flow start you can increase core node and task node, you can also decrease task node so this way elastic map reduce provide resize running job flow.
4. Elastic Map Reduce provide multiple interface such as command line interface (CLI), API, AWS management console. According to your knowledge, programming skill and your convenient you can choose any interface.
5. Hadoop divide data into multiple subsets and give each subset to more than one cluster so by chance one cluster fail it can receive data from another cluster so this way Map Reduce is more reliable.
6. MapReduce has a high processing speed as it is use Hardtop.
Pricing:
- Pricing of Amazon Elastic Map Reduce is depend upon which instance type use, type of job, how much time is consume. And one point note that each partial instance hour will be count as full hour so you have to pay for hour.















{kind=link}