
Reinforcement studying is an area of Artificial Intelligence in which you construct a shrewd machine that learns from its surroundings via interplay and evaluates what it learns in real time. A top instance of that is self-riding cars, or while Deep Mind constructed what we realize these days as AlphaGo, AlphaStar, and Alpha Zero. AlphaZero is an application constructed to grasp the video games of chess, shogi, and go (AlphaGo is the primary application that beats a human grasp). AlphaStar performs in the online game StarCraft II.
1. Fundamental Principles Of Reinforcement Learning
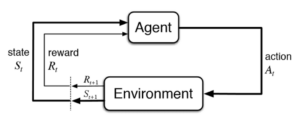
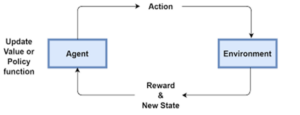
Any reinforcement studying trouble consists of the subsequent elements:
- Agent – this system controls the item of concern (for instance, a robot).
- Environment – this defines the outdoor global programmatically. Everything the agent(s) interacts with is a part of the surroundings. It’s constructed for the agent to make it appear like an actual-global case. It’s had to show the overall performance of an agent, which means it’ll do nicely as soon as applied in an actual global application.
- Rewards – this offers us a rating of the way the set of rules plays with admiration to the surroundings. It’s represented as 1 or zero. ‘1’ approach that the coverage community made the proper move, ‘zero’ approach incorrect move. In different words, rewards constitute profits and losses.
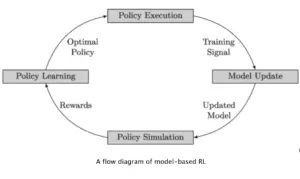
2. Model-Based And Model-Free Reinforcement Learning
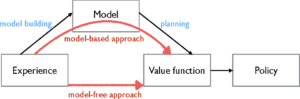
In a version-primarily based RL surroundings, the coverage is primarily based totally on the usage of a device studying version. To higher apprehend RL Environments/Systems, what defines the machine is the coverage community. Knowing completely nicely that the coverage is a set of rules that comes to a decision the movement of an agent. In this case, while an RL surroundings or machine makes use of the usage of devices studying fashions like the random forest, gradient boost, neural networks, and others, such an RL machine is version-primarily based totally.
3. Pytennis Surroundings
We’ll use the Pytennis surroundings to construct a version-loose and version-primarily based RL machine. A tennis recreation calls for the subsequent:
*2 gamers which suggest 2 retailers.
*A tennis lawn – major surroundings.
*A unmarried tennis ball.
*Movement of the retailers left-proper (or proper-left direction).
The Pytennis surroundings specs are:
*There are 2 retailers (2 gamers) with a ball.
*There’s a tennis area of dimension (x, y) – (300, 500)
*The ball become designed to transport on an instant line, such that agent A comes to a decision a goal factor among x1 (zero) and x2 (300) of aspect B (Agent B aspect), consequently it shows the ball 50 one of a kind instances with admire to an FPS of 20.
4. Discrete Mathematical Method To Gambling Tennis – Version-Loose Reinforcement Learning
Why “discrete mathematical method to gambling tennis”? Because this technique is a logical implementation of the Pytennis surroundings. And that is simple version-loose reinforcement studying. It’s version-loose due to the fact you want no shape of studying or modeling for the two retailers to play concurrently and accurately.
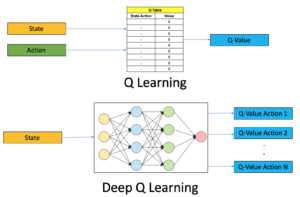
5. Tennis Recreation The Use Of Deep Q Network – Version-Primarily Based Reinforcement Learning
A usual instance of version-primarily based reinforcement studying is the Deep Q Network. Source code to this painting is to be had here. The code underneath illustrates the Deep Q Network, that’s the version structure for this painting.
6. Prior Assumptions / Problem Definition
Formally, we would like to optimize the long time praise in a Markov selection process (MDP)M =< S>, in which S is the set of states, A is the set of moves, T: S × A → S are the transition dynamics, R: S × A → R is the praise feature, ∫zero is the set of beginning states, γ is the bargain aspect and H the horizon (aka trajectory length).
7. Batch Constrained Q-studying (BCQ) Might Be Considered
a form of hybrid technique among Q-studying and actor-critic paradigms: It employs a variationally autoencoder (VAE) ω(·) to version the behavioral coverage β(·), that’s in flip used to pattern possibly moves to maximize over throughout the Q-feature update, making it appear extra like a Q-studying technique.
8. Conservative Q-Learning (CQL)
revolves across the concept of studying a conservative estimate Qˆπ of the fee feature, which decreases bounds the actual fee of Qπ at any factor. The authors display that this may correctly stay away from the overestimation bias in unexplored areas of the kingdom area this is the maximum not unusual place difficulty in offline RL.
9. Hybrid Methods
Commonly, algorithms are classified version-primarily based as quickly as they comprise a transition version somewhere. We will but take some time to in addition distinguish among version-primarily based methods: The preceding phase featured methods, that without delay used their transition fashions for coverage search, with no more steps and without the facts produced throughout digital rollouts getting used again.
10. Conclusion
Tennis is probably easy as compared to self-riding cars, however, optimistically this situation confirmed some matters approximately RL that you didn’t realize. The major distinction between version-loose and version-primarily based RL is the coverage community, that’s required for version-primarily based RL and needless in version-loose. It’s well worth noting that oftentimes, version-primarily based RL takes a big quantity of time for the DNN to study the states flawlessly without getting it incorrect.






")








{kind=link}