
Doung Cutting joined Yahoo in 2006, and he retained the word Nutch for the web crawler portion of the project. He named the storage and distributed processing portion of the project as Hadoop (Doung’s son’s toy element). In 2008, Yahoo released Hadoop as an open source project. Today, Hadoop is developed as a framework for a non-profit organization Apache Software Foundation (ASF), a global community for a software developer.

What is Hadoop?
Apache Hadoop is a Java programming based framework that allows processing of data across clusters of commodity computers using a simple programming model. It is scalable from single servers to thousand of machines, each providing computation, and storage. Hadoop uses its infrastructure to provide the high ability, the framework itself is designed to handle failures at the application layer thus delivering a highly-available service on top of the cluster of computers, each of which may be prone to failures.
In short, Hadoop is an open-source framework for storing and processing big data in a distributed way on large clusters of commodity hardware. It accomplishes following two tasks:
1. Massive data storage
2. Faster Processing
Why Hadoop?
Taking care of hardware failure cannot be made optional in Big Data Analytics. There is need of fault tolerant to store to guarantee reasonable availability. To provide data protection and fault tolerance Hadoop is used.
The Architecture of Hadoop:
Hadoop architecture consists of the following components:-
1. Hadoop Common: This package distributes file system and operating system level abstractions. It contains libraries and utilities required by other Hadoop modules.
2. Hadoop Distributed File System (HDFS): HDFS is a distributed file system that provides a limited interface for managing the file system.
3. Hadoop MapReduce: MapReduce is an algorithm that the Hadoop MapReduce engine uses to distribute work around a cluster.
4. Hadoop Yet Another Resource Navigator (YARN): It is a resource management platform. It is responsible for managing to compute resources in clusters and using them for scheduling of user’s applications.
Advantages of Hadoop:
The main benefits of Hadoop are listed below:
1. Scalable: It can scale up from a single server to thousands of servers with a little administration in structure.
2. Fault tolerance: It provides a very high degree of fault tolerance.
3. Economical: It uses commodity infrastructure or hardware.
4. Handle hardware failures: The resiliency of these clusters comes from the software’s ability to detect and handle failures at the application layer.
The Hadoop framework can store big amounts of data by dividing the data into blocks and storing it across multiple computers, and computations can run in parallel across multiple connected machines.
Hadoop gained its importance because of its ability to process a variety of data generated every day, especially from automated sensors and social networking sites.
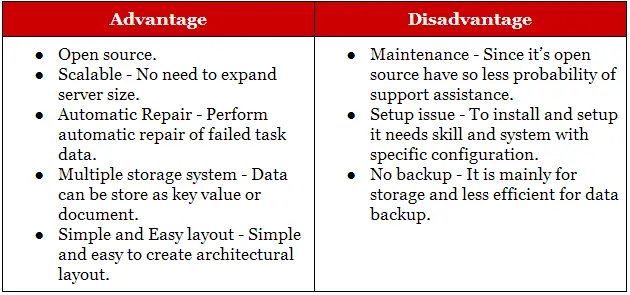
General Limitations of Hadoop:
Some limitations of Hadoop are listed below:
1. Security concerns: Hadoop does not provide encryption at storage and network levels. Therefore, government agencies and others do not prefer to keep their data in Hadoop framework.
2. Vulnerability by nature: Hadoop framework is written mostly in Java, one of the widely used programming languages by cyber criminals. For these reasons, several companies do not prefer Hadoop framework.
3. Not fit for small data: Due to high capacity design, Hadoop does not support reading of small files. It is suitable for big data.
There are some limitations of Hadoop framework, but Hadoop helps to business. Hadoop is very beneficial for large scale businesses and enterprises for storing and handling “big data”.








")






{kind=link}