
1. Lack Of Domain Knowledge
This profession is better suited to a recently appointed Data Scientist rather than one who has been with the same corporation for many years. While a recent graduate or newbie to the area may have the statistical understanding and procedures required to modify data, they need more subject expertise to ensure reliable findings. On the other hand, someone with an in-depth knowledge of the subject can better discriminate between excellent and ineffective ways, something a novice needs help accomplishing. Even after domain knowledge doesn’t grow overnight and requires time spent working in a specific area, one might take datasets from multiple domains and try to use Data Science abilities to solve the issue. As a result, the individual would become associated with data from many areas and understand the often-employed variables or properties.

2. Misconceptions Regarding The Role
At large businesses, a Data Scientist is seen as a jack of all crafts tasked with gathering data, developing models, and making sound business choices, which is a tall order for any individual. The roles in a Data Science team should be divided among different persons, such as Data Engineering and Data visualization, Predictive analytics, model construction, and so forth. At large businesses, a Data Scientist is seen as a jack of all crafts tasked with gathering data, developing models, and making sound business choices, which is a tall order for any individual. The roles in a Data Science team should be divided among different persons, such as Data Engineering and Data visualization, Predictive analytics, model construction, and so forth. The business should be clear about its goals and specialize in the tasks that the Data Scientist must do without placing undue expectations on the individual. Despite a Data Scientist holding the bulk of the required abilities, sharing the work would ensure the business’s smooth functioning. As a result, a clear description and communication about the function are needed before someone begins working as a Data Scientist in the firm.

3. Getting Right Data
In this situation, quality outweighs quantity. A Data Scientist has to understand the topic asked and respond to it by analyzing data using the appropriate tools and procedures. It is time to gather the required information only after the requirement is understood. There is no shortage of data in the current analytical Analytics environment, but having too much information without significant relevance might result in a model failing to answer the underlying business problem. The correct data with the essential attributes must be obtained first to construct an accurate model that works effectively with the company. To address this data issue, the Data Scientist must connect with the company to get sufficient data and then apply domain awareness to eliminate extraneous aspects. This is a backward elimination method, yet it is frequently helpful in most situations.

4. Selecting The Best Algorithm
This is a subjective difficulty because no such method works well on a dataset. If there is a linear relationship between the feature and the target variables, linear models like Linear Regression and Logistic Regression are commonly used. Non-linear connections, on the other hand, are better served by tree-based models such as Decision Trees, Random Forests, Gradient Boosting, and so on. As a result, it is recommended to test several models on a dataset and assess them using the measure provided. The model with the lowest mean squared error or the highest ROC curve is finally selected as the go-to model. Moreover, ensemble models, which combine multiple methods, produce superior outcomes in general.

5. Problems With Data Security
In today’s world, data security is a major problem.Because data is retrieved through several interconnected channels, social media, and other nodes, hacker assaults are more vulnerable. Data scientists need help in data extraction, consumption, modelling, and algorithm development due to the confidentiality of data. The procedure of gaining user consent is producing significant delays and expense overruns. There are no shortcuts for this element. One must adhere to the established worldwide data protection standards. Further security measures are required, as is the usage of cloud platforms for data storage. Companies must also actively adopt innovative solutions, including Machine Learning to protect against cybercrime and fraudulent operations.

6. Communicating The Results To Non-technical Stakeholders
Management and stakeholders in a firm need to be made aware of the tools and functioning structure of the models. They must make critical business decisions based on what they see in front of charts or graphs or the data provided by a Data Scientist. Presenting the outcomes in technical terms would be ineffective because those in charge would need help understanding what was being stated. Consequently, one may describe their conclusions in non-specialist’s words and even utilize the measure and KPIs decided at the start to illustrate their findings. It would include the company evaluating its performance and determining what essential areas of improvement are required for its growth.

7. Keeping Up With New Technologies
Following the most recent advances in data science may be difficult since this field is constantly growing with the introduction of new algorithms, methods, and tools. Data scientists should attend conferences, study scholarly papers, and participate in online forums to meet this challenge. They should also spend ongoing education by attending courses and obtaining certificates to learn about new technologies and practices. Data scientists may guarantee they utilize the most effective and efficient ways to analyze data and extract insights by staying current on recent advances.

8. Data Cleaning
Discovering and fixing mistakes, inconsistencies, and missing data in datasets is known as data cleaning, sometimes known as data preparation. It is a critical stage in data science since the accuracy and reliability of any analysis or model are strongly dependent on data quality. Data cleaning is a tricky process for data scientists because of the vast number and complexity of data and the different data sources and formats. Data scientists may solve this issue using various tools and methodologies, such as data profiling, data wrangling, and data validation. They can also use automated data cleaning techniques to discover problems and interact with subject matter experts to assure data accuracy. Effective data-cleaning procedures can lead to more accurate insights and enhance the overall quality of analysis and decision-making.

9. Overfitting
Overfitting is a prevalent problem in data science. It occurs when a model grows too complicated and fits the training data too well, resulting in poor performance on new, previously unknown data. It happens when a model is trained on a tiny dataset or with excessive features, causing the machine to memorize the training data rather than understand the underlying patterns. To overcome overfitting, data scientists can utilize regularization, cross-validation, and feature selection techniques. Methods for removing unnecessary or excessive features can improve model performance and reduce overfitting. Using these strategies, data scientists may construct more robust models that perform well on training and testing data.
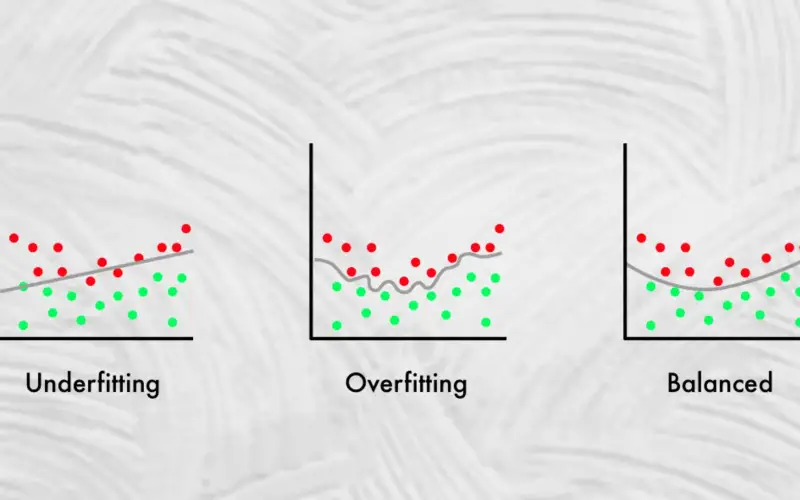
10. Scaling Models
In data science, scaling models is a difficulty since larger datasets need more computing resources and may surpass the memory capacity of typical machine learning techniques. Data scientists can employ tools like distributed computing, parallel processing, and cloud computing to tackle this difficulty. Distributed computing is dividing data into smaller parts and processing them on numerous devices simultaneously. Parallel processing uses many processors within a single system to evaluate data quickly. Cloud computing allows data scientists to handle massive datasets without costly hardware expenditures since it provides scalable computing resources on demand. Data scientists may use these strategies to scale their models to analyze more datasets and draw insights quicker, boosting the efficiency and efficacy of their studies.







")






{kind=link}