
Emerging privacy legislation like GDPR increasingly mandates demonstrable data protections for consumers. Meanwhile, data scientists face heightened ethical obligations to minimize the collection and leakage of superfluous personal data. Technical solutions that transform sensitive attributes or restrict computations provably preserve privacy while sustaining analytic utility. As analytics expands amidst proliferating data sources, proactively managing privacy-utility tradeoffs around sensitive datasets requires greater investment into mitigating technologies aligned with ethical principles.
I outline the top 10 advanced mathematical methods that enable privacy-preserving analytics while protecting sensitive data through rock-solid information security guarantees grounded in academic literature. These techniques UC Berkeley differential privacy pioneer Cynthia Dwork proclaimed “fundamentally changed our conceptualization of privacy” relative to preceding controls like consent notices.
Mathematically rigorous privacy-enhancing approaches operationalize cutting-edge cryptography, distributed systems, machine learning, and data science to uplift data protection to 21st-century challenges. Innovations like homomorphic encryption, secure multi-party computation, and federated learning promise to computationally enforce data safeguards aligned with people’s expectations of trust and visibility.
1. Differential Privacy
Differential privacy comprises an entire system for publicly sharing statistical summaries about a dataset by carefully introducing calibrated noise. This ensures that the inclusion or exclusion of any individual record does not disproportionately impact the output statistics within a restricted range. Differential privacy works by minimizing assumptions about what new information can be explicitly or implicitly inferred through queries on a dataset. The epsilon parameter defines the overall privacy loss budget for calibrating the noise level based on the application’s accuracy and precision requirements per query. While complex for practitioners to implement properly, differential privacy represents one of the strongest privacy guarantees in the literature with demonstrable usability across diverse analytics use cases.
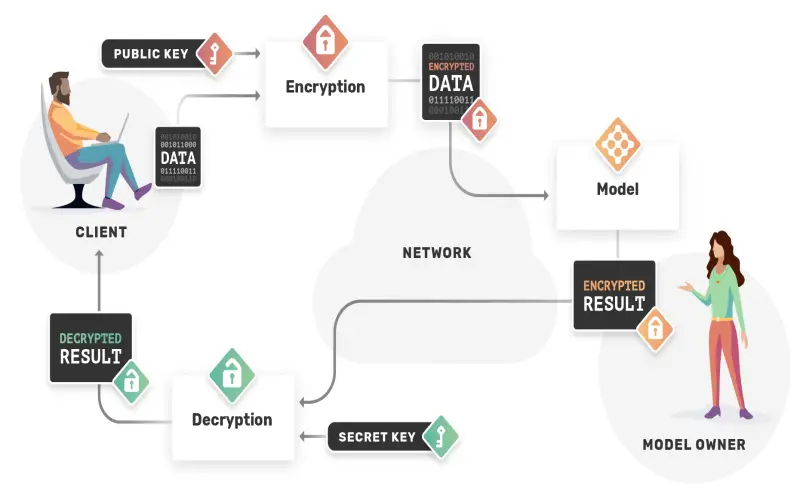
2. Homomorphic Encryption
Homomorphic encryption refers to a suite of techniques allowing mathematical operations to be carried out on encrypted data without requiring preliminary decryption. The underlying data remains encrypted from end to end while permitting certain restricted computations by untrusted parties. Fully homomorphic encryption can handle arbitrary operations but runs slowly given current cryptography limitations. Somewhat homomorphic encryption restricts the feasible computations while improving performance. As cryptography research and cloud technology continue advancing, homomorphic encryption promises to enable rich analytics through secure multi-party computation without ever exposing raw data.
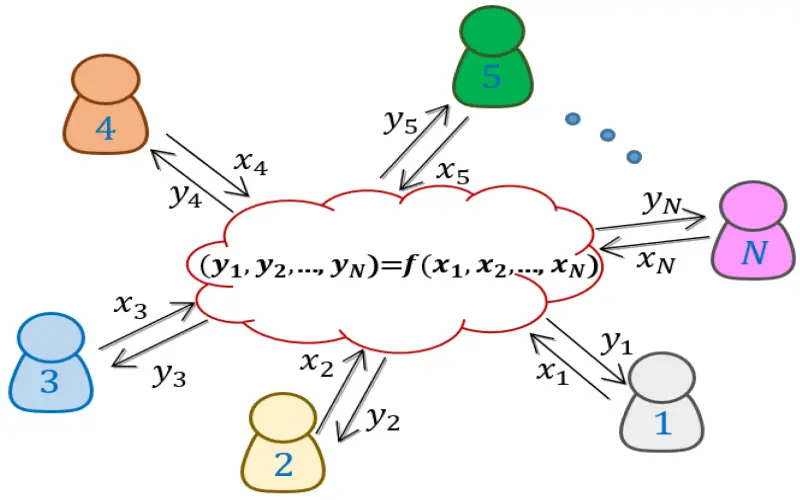
3. Multi-party Computation
Multi-party computation distributes datasets among several non-colluding entities and provides a coordination protocol enabling secure aggregated analytics. Each party leverages secure enclaves to run computations on their partial dataset. Locally computed intermediate statistics pass between parties according to the protocol without external exposure. At no stage is private data exposed during the collective analytics. Beyond distributing trust across multiple entities, multi-party computation parallelizes data processing across staged analytic workflows. However it requires additional coordination complexity and can pose scalability constraints for extremely high velocity or real-time workloads across numerously massive datasets.
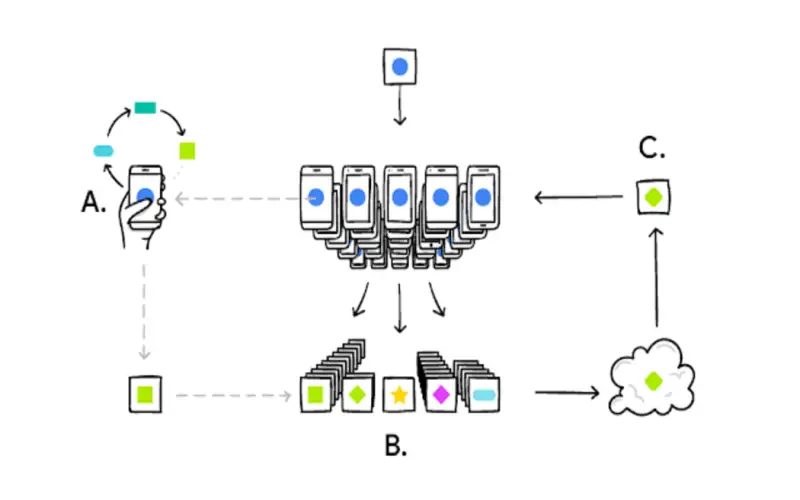
4. Federated Learning
Federated learning comprises a technique to train machine learning models at scale without first aggregating raw datasets in a central location. Models initialize with a common framework and then get updated locally at each participating entity using only their distinct raw private data. Only model parameters transfer between parties per iteration, not the underlying data. This technique anticipates the increasing ubiquity of edge devices and restricted bandwidth in IoT ecosystems. As specialized hardware at the edges becomes more capable over time, the practicality of federated learning strengthens for particular use cases. However, the technique does not prevent reconstructed data leakage without additional safeguards.
5. Ensemble Privacy-Preserving Techniques
Hybrid approaches combine preprocessing techniques like generalization and partial anonymization with encrypted computation. For instance, an encrypted dataset gets transformed through multi-party computation then differentially private noise inserts during aggregate reporting. Chained techniques incorporate defense-in-depth while concentrating the impact on utility or performance into particular phases. However, encapsulating the precise cumulative privacy guarantees grows more intricate with composite methods. Ensuring consistency with ethical principles warrants ongoing governance.
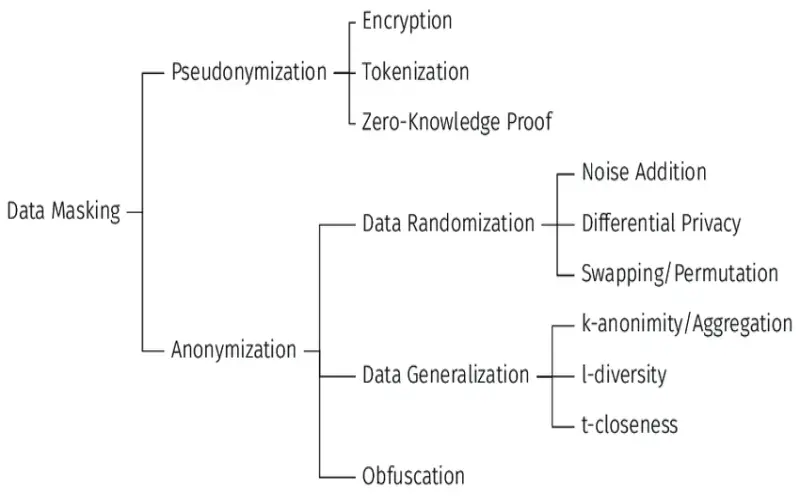
6. Data Masking
Data masking partially obscures information using random replacements of confidential attributes. Masking transforms parts of the data in situ, meaning the original records remain recoverable later with the decoding key. Organizations heavily apply masking to create privacy-enhanced datasets for lower trust level analytics without fully exposing real data. Data masking represents a straightforward substitution method to enable wider access without full exposure. Effective masking functions require careful design to uphold fitness-for-purpose in target analytics use cases.
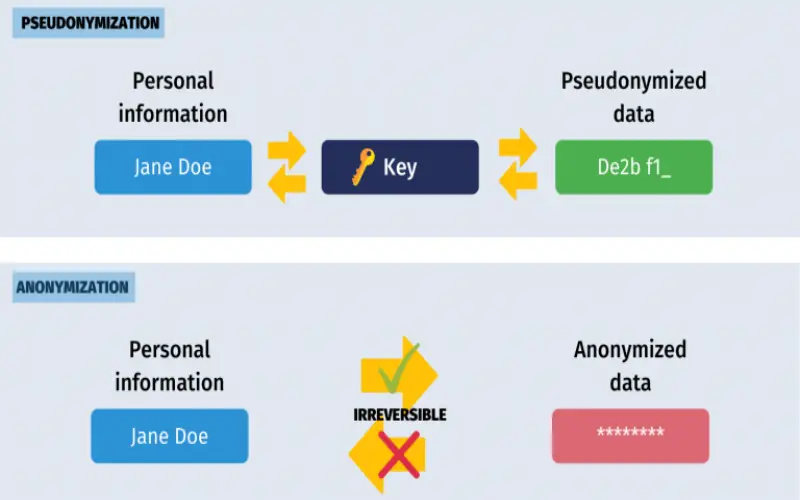
7. Pseudonymization
Pseudonymization substitutes identifiable information like names, national identifiers, home addresses, or phone numbers with artificial attributes like randomized user IDs. For example, email addresses could systematically map to database keys. Pseudonymization gets applied pervasively as an initial line of defense but remains vulnerable to re-identification attacks with enough external data sources. Properly implemented pseudonymization demonstrably deters the feasibility of recognizing individuals through typical means. When coupled with additional controls like multi-party computation, it meaningfully augments data utility compared to full dataset anonymization.
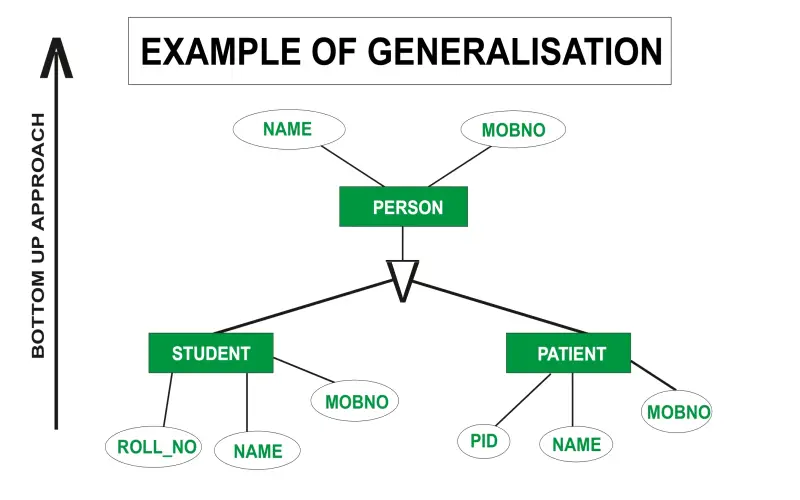
8. Generalization
Generalization transforms granular attributes into broader categories through techniques like binning, k-anonymity, l-diversity, or t-closeness. For example, instead of listing precise geolocations, data generalizes to the zip code or census block level. This reduces fidelity but diminishes uniqueness which compounds re-identification difficulty. Like other preprocessing methods, the parameters require careful tuning around target analytic needs to maximally preserve relevance. Generalization frequently operates alongside complementary controls that continue curtailing what inferences get drawn during analysis.
9. Data Swapping
Data swapping pseudo-randomly exchanges confidential attributes between selected records. This technique partially anonymizes datasets, though the original data stays recoverable with the decoding scheme. Swapping individual columns plausibly disrupts the correlation between quasi-identifiers and sensitive variables. Because simple whole-column swapping over-distorts datasets, constrained methods aim to minimize distortion, like geo-locational swapping within the same neighborhoods or swapping ages within thresholds. Deployed judiciously alongside other protections, swapping demonstrably reduces pedigree risks without fully blocking analytics.
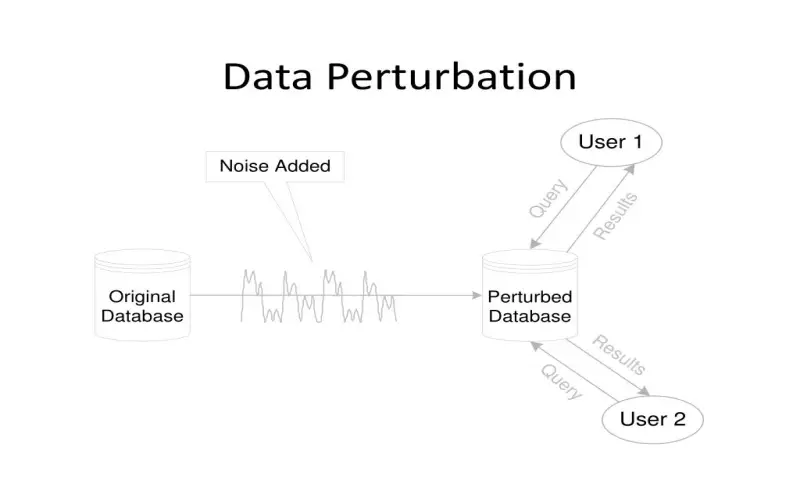
10. Data Perturbation
Data perturbation injects mathematical noise into types of variables using absolute or ratio adjustments relative to actual underlying values. Perturbative methods similar to differential privacy restrict elevated contributions by any individual to the aggregated analytics. Data perturbation intentionally reduces apparent data quality to preclude pinpoint outcomes through record linkage attacks. The perturbation gets dynamically calibrated per computational context. For example, more uncertainty is inserted for group averages versus distributions to retain sufficient usefulness given the target analysis type. Advanced solutions incorporate perturbative steps among other controls.















{kind=link}