
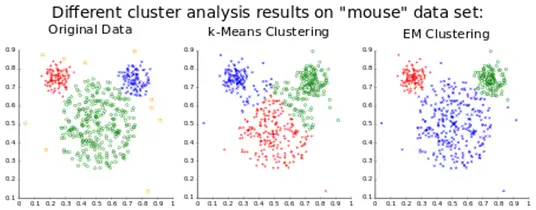
1. K-means
K-means is a cluster analysis technique that makes a group of similar elements from a set of objects by creating k groups. We validate the results by comparing the groups (called clusters) with a predefined classification. K-means is an easy algorithm to implement on Weka as well as Tanagra.
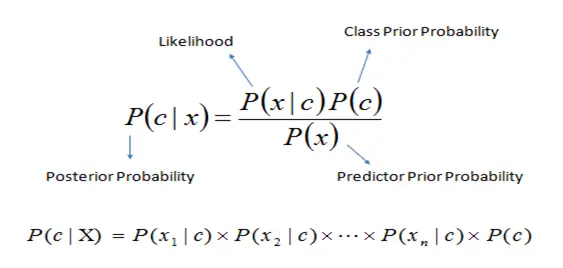
2. Naïve-Bayes
Naïve-Bayes is comparatively a faster classification algorithm. As the name suggests, it works on the Bayes theorem of probability. The aim is to predict the class of unknown data module. We can implement the algorithm for various applications like real-time prediction, text classification or recommendation system, etc.
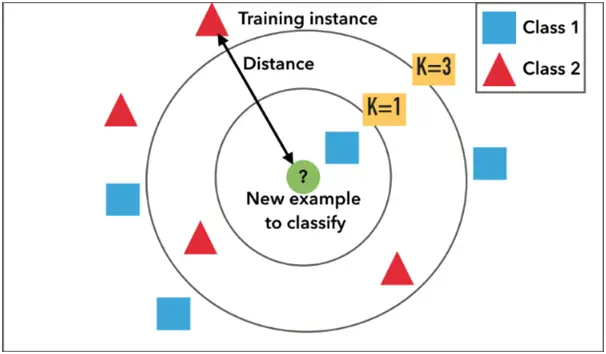
3. KNN
K-Nearest Neighbour is a data mining technique that works on a historical data instances with their known output values to predict outputs for new data instances. By implementing this algorithm either on Weka or Tanagra, we can get the desired result.
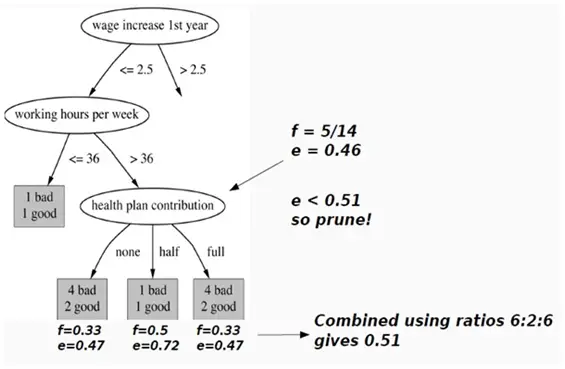
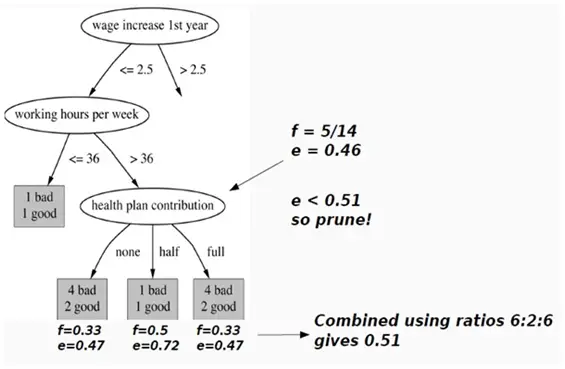
4. ID3
Decision trees are the supervised learning algorithms which are easy to understand as well as easy to implement. The goal is to achieve perfect classification from given training data set with minimal decisions. ID3 uses Information Gain concept for its implementation.
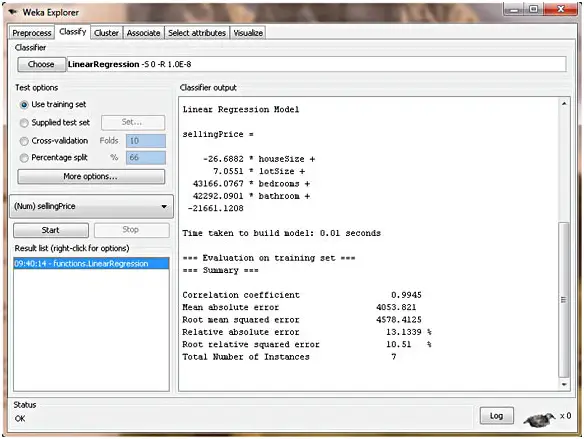
5. Regression
In this algorithm, we have a set of binary or continuous independent variables. Using this set, we predict the values of the dependent variable through regression. We can use this algorithm for the prediction of numbers like age, weight, temperature, salary, etc. For each case in the training data, this algorithm estimates the target value as a function of predictors.
6. C4.5
C4.5 is an extension of a decision tree algorithm known as ID3. C4.5 is commonly referred to as a statistical classifier asthe decision trees generated by this algorithm can be used for classification purpose.
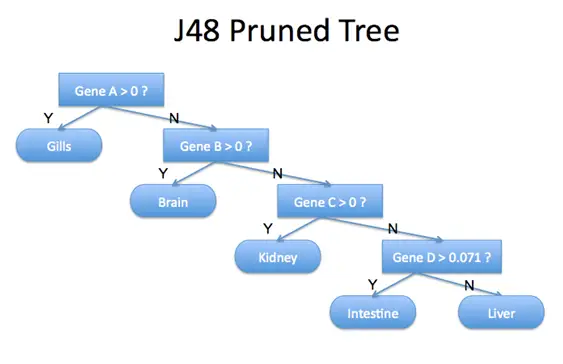
7. J48
J48 is an algorithm developed by WEKA for the decision tree algorithm ID3. J48 is an open source exertion of C4.5 in Java. J48 includes some additional features which account for the missing techniques (in ID3 or C4.5) like decision tree pruning, missing values, derivation of rules, continuous attribute value ranges, etc.
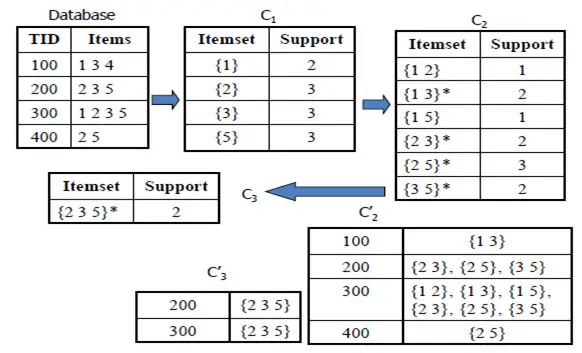
8. Apriori
The goal of Apriori algorithm is to derive association rules by finding frequent item sets from a transaction data set. To find frequent item sets is not a trivial task. The frequent itemsets are used to generate association rules with confidence larger(or equal) than a user specified minimum confidence. This algorithm is one of the most useful algorithms for data mining.
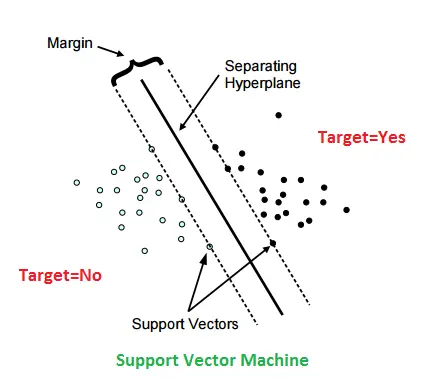
9. Support Vector Machines
Support Vector Machines (SVM) offer one of the most accurate methods amongst them all. The robust algorithm requires only a couple of examples for training and is indifferent to the number of dimensions. The algorithm has a sound theoretical foundation.
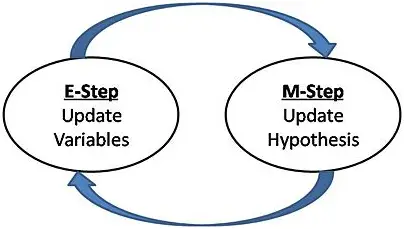
10. EM
The Expectation Maximization algorithm has finite mixture distribution which provides a flexible mathematical approach to the clustering. The algorithm also aims to approach towards modeling of data observed on random phenomena. The goal is to focus on the use of normal models, which can be used for the clustering of continuous data so as to estimate the underlying density function.








")






{kind=link}