
Implementing a comprehensive backup and recovery strategy is crucial for any database environment. Unplanned downtime or data loss can have devastating consequences for an organization. However, many database administrators fail to prioritize backups until disaster strikes. Developing robust policies, procedures, and systems for protecting data should become part of the foundational work of any DBA role. In this article, I outline key database backup and recovery best practices that DBAs should have in place. Following these top 10 strategies will help safeguard database availability, and integrity and improve resilience. While specifics may differ across database platforms, these overarching principles will apply widely.
1. Develop A Comprehensive Backup Plan
The cornerstone of any successful backup and recovery scheme is a well-designed backup policy. This comprehensive document should outline the frequencies, storage locations, retention periods, and technologies utilized in an organization’s database backups. It will serve as the rulebook for DBAs to follow when configuring and managing database protection. Crucially, the backup plan should align with defined recovery point objectives and recovery time objectives. These metrics specify how much potential data loss is acceptable and the timeframe to restore database functionality. The backup frequencies, retention policies, and favored technologies should all map to meeting established RPOs and RTOs.

2. Perform Effective Backup Management
Simply running database backup jobs is not enough for robust protection. DBAs need to actively manage the backup process end-to-end. This includes monitoring job statuses, sending notifications on failures, validating backup file integrity, tracking capacity usage, and adhering to the pre-defined backup policy. Put checks in place to safeguard backup performance and availability. For instance, implement scripts to automatically verify all database backup sets are completed successfully without errors. Build dashboards to track operational metrics like backup durations, deduplication ratios, storage consumption, and failure rates. This oversight is essential to maintain protection aligned to RPO/RTO targets.

3. Perform Periodic Database Restore Testing
The best way to validate backup integrity is by regular restore testing. DBAs should routinely attempt to rebuild databases from current backup sets to prove recoverability. This exercise builds operational confidence and preparedness for actual recovery scenarios. Ideally, target testing databases from all backup streams quarterly or after any substantive platform changes. If gaps are found, it warrants identifying root causes and revisiting backup strategies before real-world implications occur. Never assume protection levels until demonstrated via mock restore exercises.
4. Draft And Communicate Backup And Recovery SLAS
Ambiguous or outdated SLAs have complicated communication during past high-severity incidents. I recommend open dialogue between DBAs and management around developing pragmatic yet aspirational targets given budget constraints. We once aimed too aggressively for a two-hour RTO that leadership was unwilling to properly fund from a staffing and infrastructure perspective. Share SLA specifics across technical and business users so responsibilities are transparent. For example, application owners may need to enable specific recovery modes while DBAs focus on restores. Revisit agreements periodically and communicate changes.

5. Avoid Backing Up Databases To Local Disks
Storing backup files on local disks attached to the database server may simplify setup but concentrates risk. If the server suffers failure, accessibility to backup data is simultaneously lost. Follow best practices to backup databases over the network to separate, resilient storage immune from database server outages. Popular options include SAN/NAS devices, NFS shares, cloud object stores, and external drives. Weigh the benefits and drawbacks of each based on bandwidth, security, retention, and recovery requirements. Learning this lesson the hard way early in my career taught me to justify the cost of the network share.
6. Justify The Cost Of The Network Share
Server-less database protection does warrant considerable storage investments. Costs stem from procuring high-performance arrays, added capacity consumption, and network considerations. Therefore, DBAs should provide sound financial justification around this model by quantifying the value of risk mitigation. Calculate exposure threats in terms of lost revenue per minute of downtime, potential legal implications, and reputational harm. Compare this to the hard-dollar outlays for robust shared storage environments. This business case evaluation helps secure organizational funding based on true availability requirements.
7. Do Regular Fire Drill Rebuilds And Restores
As emphasized previously, test recovery capabilities at regular intervals to avoid surprises when restores are critical. Schedule fire drills treating simulations as full-blown emergencies, potentially even disabling existing backups to prevent the temptation to cheat. Rebuild servers and restore database copies from backup to validate procedures. Engage cross-functional teams and set aggressive timelines aligned to SLAs. Debrief afterward to recognize wins, identify gaps, and agree on improvements. In my experience both participating in and leading fire drills, I find the short-term pain nearly always proves worth long-term preparedness gains.

8. Keep Management Informed On Restore Time Estimates
While DBAs scramble to restore databases during outages, anxiety builds for management concerned with business impact. Set appropriate expectations by providing frequent updates with time estimates based on incident severity, backup and recovery mechanisms available, resources involved, and processes required. Convey transparency around challenges encountered but reaffirm capabilities to deliver within SLAs. In the past, sharing regular restoration updates with estimated completion times has eased tension. I aim to provide reliable expectations but caution against guarantees, instead focusing efforts on systematic progress. Once after 22 straight hours recovering Oracle clusters, our executive sponsor’s faith in the team helped motivate us through the final stretch rather than adding more pressure.

9. Trust No One
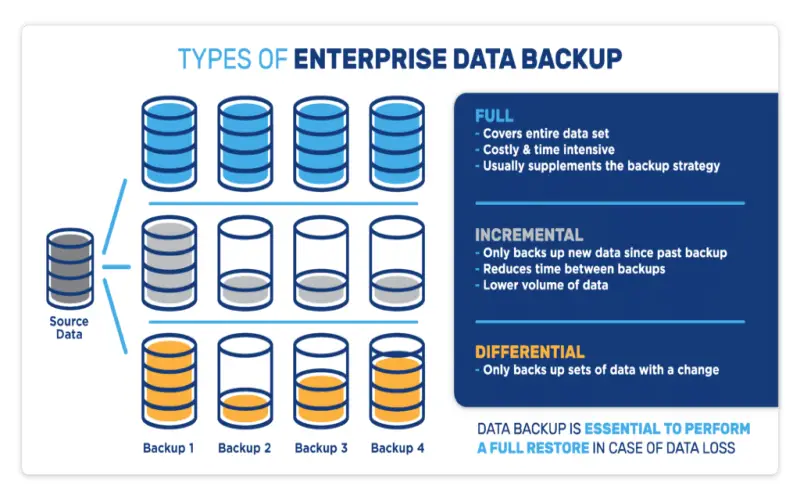
Despite best efforts to architect fault-tolerant environments, backup data remains vulnerable to malicious or inadvertent modification. No single safeguard eliminates the risk that critical backups may fail when urgently needed. Protect business continuity by implementing different layers across technology, staff, and locations. Examples include filesystem, data protection manager, dump, incremental, differential, snapshots, or replicas.

10. Use Different Types Of Backups
Experience has engrained in me a healthy paranoia around entrusting any one form of backup or administrator. Once a disgruntled employee with privileged database access corrupted tables and then destroyed Physical backups as retaliation before resigning. Without separately managed virtual machine snapshots, we may have failed to meet steep SLAs. Now I endorse distributing oversight across backup types and staff with the least privilege in mind.








")






{kind=link}