As artificial intelligence & machine learning become more complex, there is an increasing need for transparency & explainability. Organizations require insights into how models arrive at decisions to build trust and ensure fairness. Explainable AI (XAI) methods help data scientists comprehend model behavior, identify biases, and convey results to stakeholders.
I outline the top 10 XAI tools IT teams can implement to enable responsible and interpretable machine learning. Powerful deep learning models may demonstrate incredible accuracy but act as “black boxes” offering little visibility into internal workings. Explainability and accountability matters across use cases from credit approval decisions impacting individuals to medical imaging diagnoses with serious health consequences. Techniques like SHAP and LIME shine light inside the black box.
Activation maximization visually indicates what input patterns a convolutional neural network focuses on. DeepSHAP combines the best of both. As part of model development and ongoing performance validation, DBAs need to evaluate model explainability across training, testing, and production stages. I compare the leading transparency tools to augment machine learning and satisfy XAI requirements.
1. SHAP
SHAP (Shapley Additive exPlanations) is an open-source XAI library to explain individual predictions and whole models. It connects optimal credit allocation with local explanations using Shapley game theory values. As a model-agnostic method, SHAP applies to all machine learning explainability requirements and avoids several shortcomings of LIME. The consistent and theoretically grounded SHAP values add efficiency for analyzing feature impact. TreeSHAP builds on KernelSHAP for further computational performance gains. API simplicity makes SHAP integration straightforward. Output visualizations including summary plots effectively communicate explanation results.
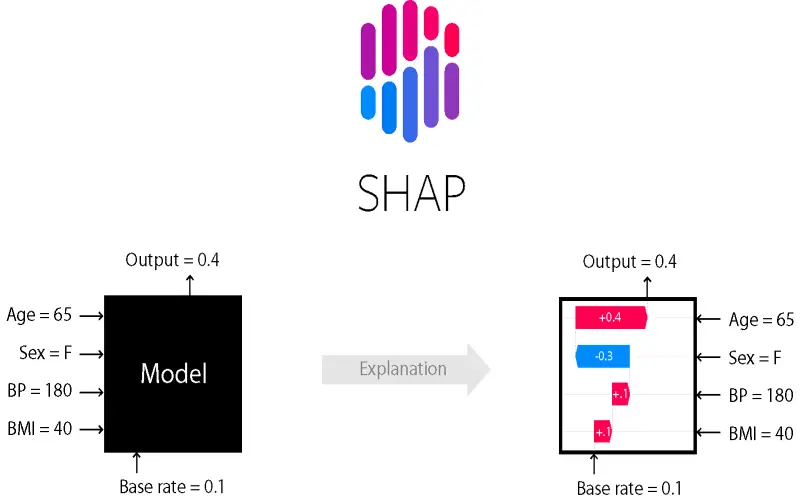
2. LIME
LIME (Local Interpretable Model Agnostic Explanations) offered an early approach to peek inside the black box and provide local surrogate explanations for individual predictions. The LIME Python package handles model transparency for tabular data as well as text and images. It constructs more easily understood linear representations of nonlinear model behavior in the locality of specific data samples. By editing original input and observing effects on output, LIME highlights influential features. It suits scenarios lacking sufficient data volume for global analysis. While useful for localized insights and model comparison, as a linear approximation method, LIME has difficulty with image classifications and complex neural networks.

3. ELI5
For straightforward implementations, ELI5 (Explain Like I’m 5) enables fast AI inspector functionality in Python for debugging machine learning models and pipelines. It automatically computes feature importance measures for a range of estimators from sci-kit-learn. ELI5 handles permutations as well as basic SHAP method integration for data visibility. Standard usage requires minimal modification to the model code. HTML reports visualize estimator inspection which aids model selection and parameter tuning. Lightweight and easy to use, ELI5 makes a handy toolkit addition for everyday interpretability. For advanced explanation needs, it works best combined with packages like SHAP or LIME.

4. What-If Tool
Google open-sourced the What-If Tool for easy experimentation and understanding of any classifier. It enables interactive probing through counterfactual testing and an intuitive visual interface. Users can edit input data points and immediately observe the impact on key model outputs. This supports an “inspect and edit” workflow to quickly validate or debug models. Beyond entering custom data, the tool automatically generates helpful counterfactual examples. By showing minimal changes required to flip a prediction, counterfactuals isolate critical features that tipped the result. The What-If Tool also computes feature attributions with high-performance integration for TensorFlow models.

5. AIX360
IBM’s open-source AIX360 toolkit compiles state-of-the-art algorithms for AI explainability, fairness, bias mitigation, robustness, and trust. It brings accessible and unified implementations suitable for business scenarios across banking, insurance, human resources, and more. With over 50 methods, the expansive toolbox accelerates AI transparency and ethical compliance. For clear explanations, AIX360 contains popular techniques like LIME and SHAP as well as IBM’s own contrastive and counterfactual solutions. With standardized public benchmarks and interfaces, users can rigorously evaluate bias and explainability. The toolkit enables reproducible XAI research while lowering barriers to trustworthy enterprise adoption.

6. Skater
As a unified framework for post hoc interpretation and explanation, Skater grants model transparency for all stages of development. It delivers global, local, and agnostic interpretability capabilities through feature importance metrics and perturbations. Skater enables insights into any black box system, even for online or already deployed models. By wrapping sklearn and Keras models with a common interface, the library abstracts complexity into an intuitive workflow. It widely supports tabular data, text, and images with a built-in visualization dashboard.
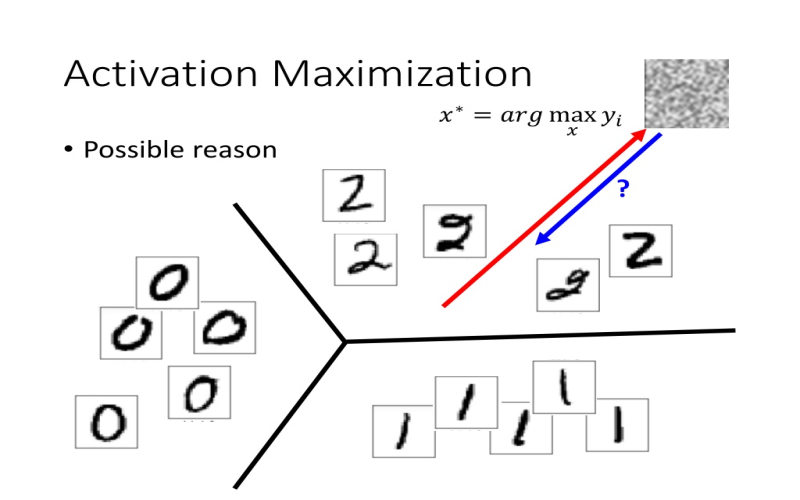
7. Activation Maximization
Deep neural network decisions depend on activated nodes through complex computational graph flows. Activation maximization directly reveals patterns that maximally activate individual convolution filters, nodes, or other components. By backpropagating from activation to input space, the method synthesizes archetypal input images highlighting visual features that neurons learn to detect. Researchers leverage activation maximization to diagnose flaws, interpret behavior, and advance architecture designs for computer vision models. The inductive bias representations build intuition into opaque systems. For convolutional neural networks, activation atlas visualization maps thousands of maximal inputs to their corresponding filters. This further demystifies hidden computations and demonstrates how hierarchical representations emerge in deep learning.
8. DeepSHAP
DeepSHAP significantly improves computational efficiency over SHAP for deep learning feature attribution. It combines gradient-based attribution with Shapley values to achieve high speed without sacrificing consistency guarantees. Deep learning tasks involve massive input dimensions spreading influence across thousands of interacting parameters. Exact Shapley calculation requires exponential item evaluations, becoming intractable for neural networks. DeepSHAP solves this through polynomial approximation assisted by gradient-based attributions.
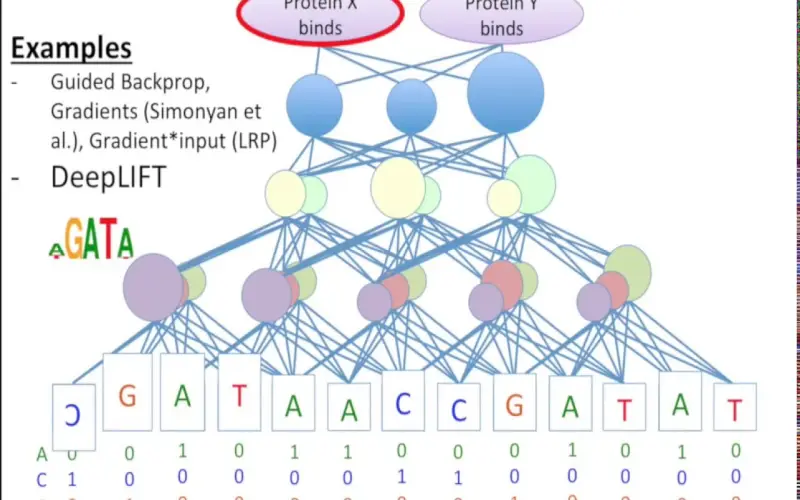
9. DeepLIFT
The DeepLIFT approach compares activation differences against a reference state to assign contribution scores for neural network outputs and layers. As a backpropagation-based method, DeepLIFT functions similarly to other gradient attribution methods but with a formal reference connection. It helps debug models by ranking input features according to a positive or negative impact on specific outputs. Researchers apply DeepLIFT to domains like genomic variant classification and chemical toxicity prediction for enhanced transparency. Unlike LIME which struggles with image inputs, DeepLIFT is well-suited for computer vision tasks.
10. CXPlain
Microsoft CXPlain toolkit specializes in text classifications with interactive visualization to enable the understanding of complex language models like BERT. It delivers human-centered local explainability through contextual decomposition. An intuitive user interface highlights influential words and relationships within document passages that lead to predictions. Unlike post hoc methods only rationalize model decisions after the fact, CXPlain takes a human-in-the-loop approach allowing non-experts to continuously validate model relevancy against intentions during training cycles. This ensures final language models behave as desired for business use cases. With interactive experimentation, developers build appropriate real-world semantic representations.








")






{kind=link}