
Machine Learning is a crucial part of Artificial Intelligence (AI). In AI training, there are generally 3 key steps involved: Data gathering, in which you gather data; model training, in which you train the machine with a way to understand the relation between data; and deployment, in which the model for the real-world use case. Supervised Learning is a type of Machine Learning and can be divided into two classes: Regression and Classification algorithms. Regression type is used when you need to predict continuous values, like predicting a person’s salary, age, or stock marketplace developments. On the other hand, Classification algorithms are used when you need to predict discrete values, which include true or false, Yes or No, zero or 1, or skip or fail. In this article, we will explore the Top 10 Machine Learning Algorithms for Predictive Analytics.
1. Linear Regression
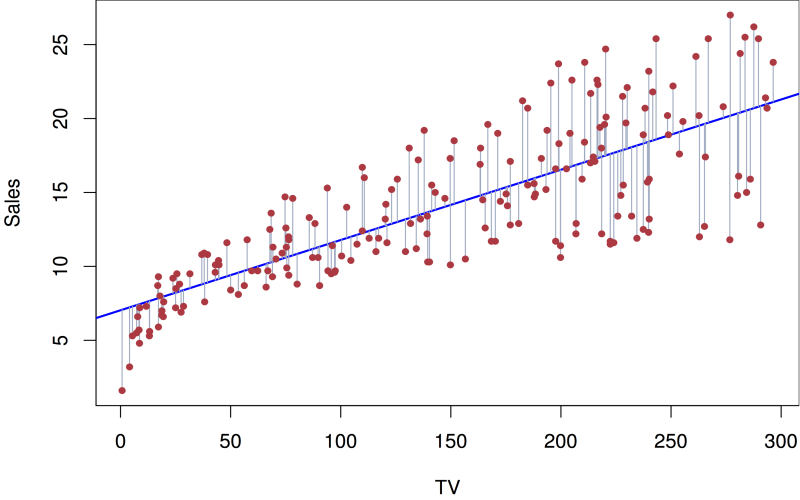
Linear regression is a simple concept in statistics that helps us see how singular data is related. It’s like drawing a map among one issue (like how a business enterprise spends on ads) and any other aspects (like how much money they make from the ones ads). For instance, an advertising team can use it to understand if there may be a link between their advertising spending and the money they earn. This helps them understand their income, making it simpler to plot their budgets and allocate their assets wisely.
2. Multilinear Regression
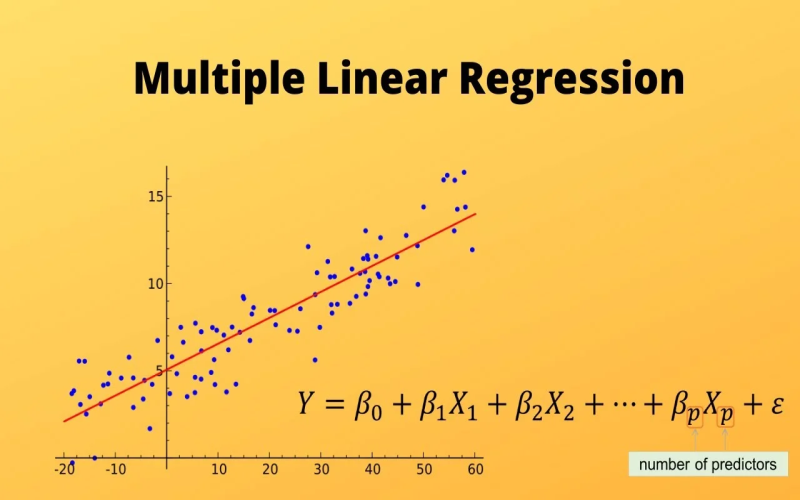
Multiple Linear Regression is another type of statistical model to understand what number of different things are related to one fundamental component. It’s like finding out how a group of things (like top, weight, age, and workout hours) are connected to something critical (in this case, blood strain). This method helps in predicting destiny values of that crucial element, like estimating someone’s blood pressure based totally on one’s factors. The output variable is what we’re seeking to expect, and that is blood stress in this example, and the input variables are the elements we are using to make those predictions.
3. Logistic Regression
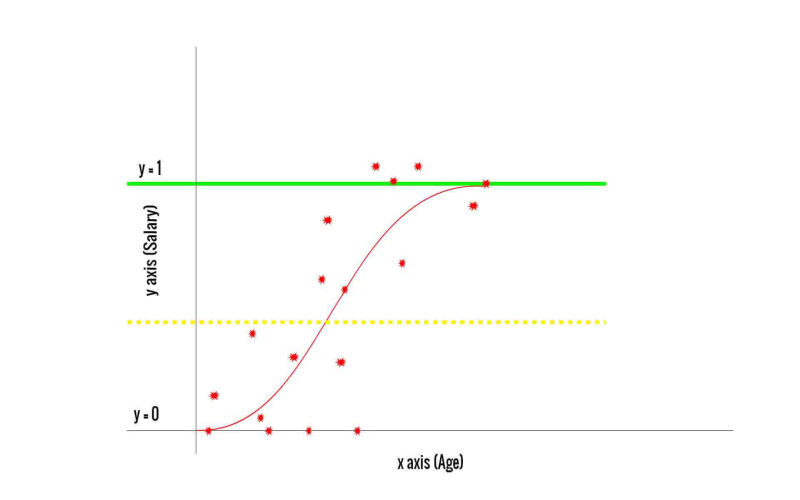
Logistic regression, also known as logit regression. It is a method used for binary regression problems. It helps us find if something belongs to one group or every other, like finding if an image is of a cat or not. It estimates the possibility that something falls into one category but, broadly speaking it sorts data into two categories: the primary group and another secondary group. These models are useful for tasks in which we want to sort input data into clean groups such as spotting similar photos, detecting junk mail emails, or clinical diagnoses.
4. Naïve Bayes
Naive Bayes is a technique that helps us make predictions in which data is grouped into several different categories. It makes use of the Bayes Theorem and finds the relation of how likelihood it is that something belongs to a category based totally on different factors at the same time as assuming those elements aren’t associated with each other. Imagine a software that identifies plants using Naive Bayes. Then it will use plant features like length, shade, and type to determine which plant and picture shows.
5. Decision Tree
Decision Trees are very popular in Machine Learning and Data Science. They work like a tree with branches and help classify things primarily based on their characteristics. Let’s understand it by taking an example, if we need to recognize if someone will buy a product, we can use a Decision Tree to break up people into various categories based on their age, income, gender, etc. Then, we can understand the possibilities of every category shopping for the product. This enables us to predict purchase counts more accurately than methods like logistic regression.
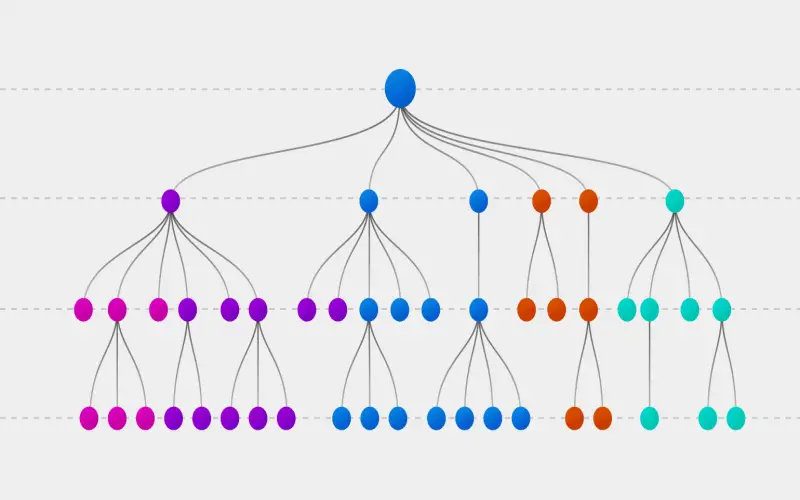
6. Random Forest
A random forest algorithm is a technique that uses a bunch of decision trees to discover patterns and make better predictions. It works by using several decision trees working on the same problem. Let’s take an example and understand, that in clinical diagnosis, you could gather patient information like age, gender, and lab test outcomes to determine if a patient has some disease or not. Instead of simply one choice tree, you operate lots of them, and everyone looks at a distinct part of the problem. This makes the prediction more accurate and reliable.
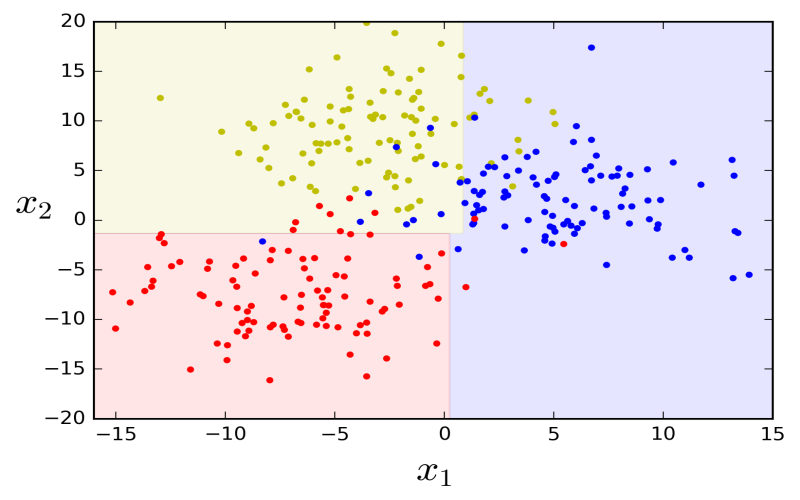
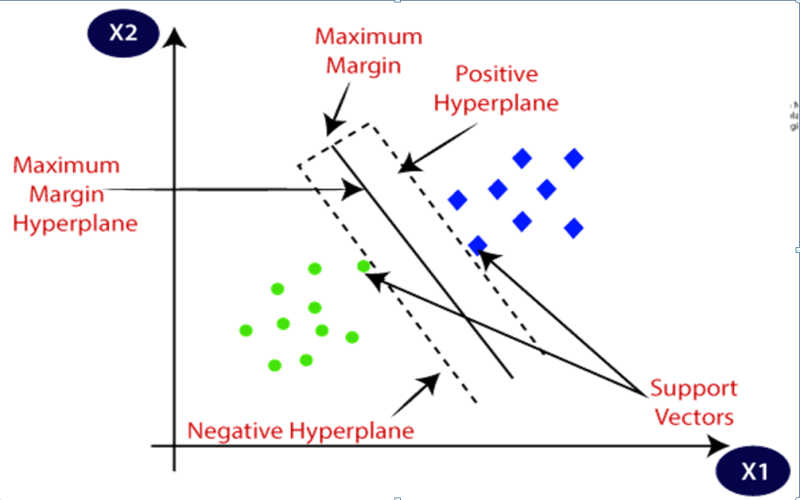
7. Support Vector Machine
A support Vector Machine (SVM) is a type of method in which we sort data into exceptional categories, by selecting objects in a photo. It does this by drawing a line (or a more complicated form) around a special object on which the model is trained, and it tries to make this line as specific as possible. This difference, called the margin, enables us to separate the objects. Let’s have an example, in face detection SVM model can find faces accurately by drawing a line between pixels that appear like a face and those that do not.
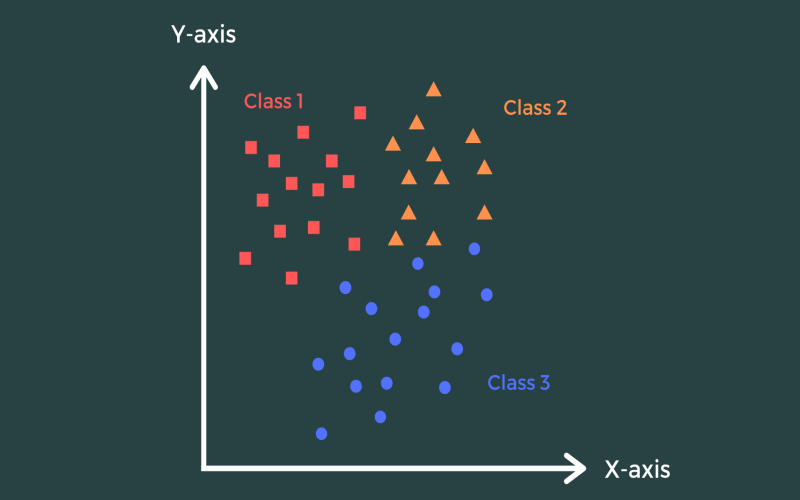
8. KNN (K-Nearest Neighbours)
K-Nearest Neighbours (KNN) is a model that uses a getting-to-know approach, it’s used for sorting data into various categories or predicting values. It doesn’t make any assumptions about the data distribution and mainly works by evaluating the relationship between new information and trained data. To decide which group the new information belongs to, KNN tests the similarity with its k nearest neighbors and outputs to the category that a maximum of them belong to.
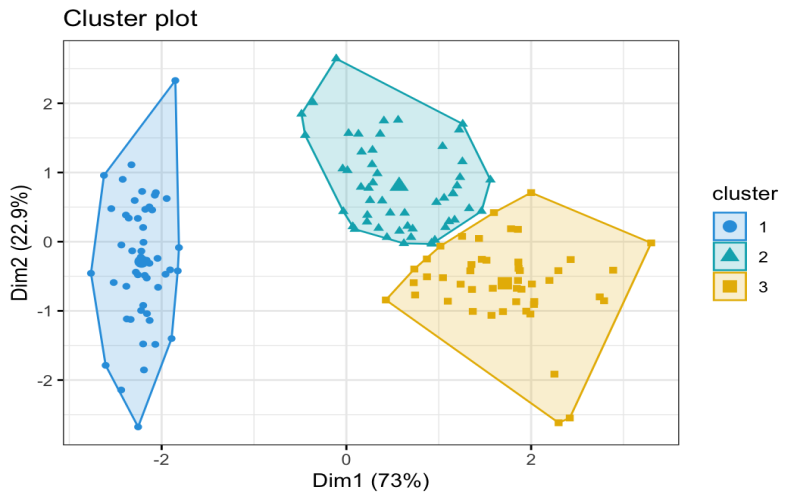
9. K-Mean Clustering
K-method clustering is a widely used unsupervised learning approach for locating patterns in information. It combines data into K clusters with each cluster consisting of various relevant features in it. These central features replicate the typical traits of the information of their respective clusters. The k-method method has many applications including dividing customers into various categories for advertising and marketing, reading retail income, or sorting snapshots and other tasks like facial recognition.
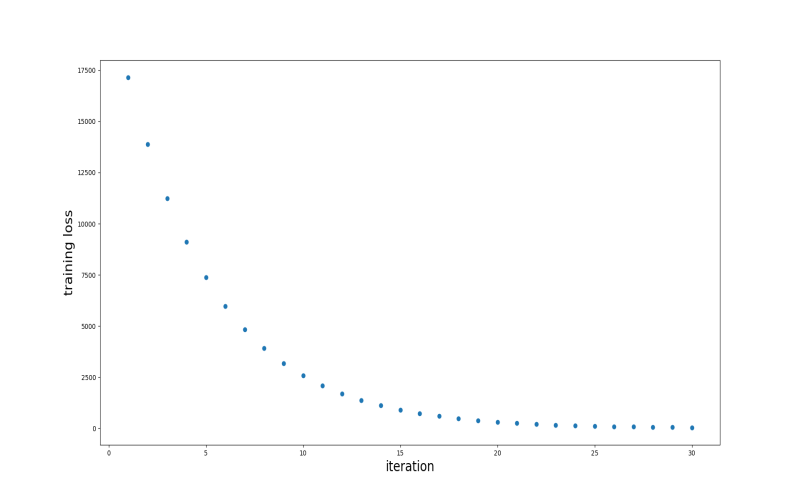
10. Gradient Boosting
Gradient boosting is an algorithm that uses ensemble learning. In this, they create a sequence of weak primary models to create a singular strong prediction model. This process reduces mistakes and helps models generalize. It starts with an easy initial version that makes fundamental guesses, in which it classifies statistics mainly based on whether it is above or below an average. This serves as a start line. In each step, it builds a better new version that corrects the mistakes made using the preceding ones.






")








{kind=link}