
Internet-scale applications need flexible data models with superior performance scalability. Relational databases often struggle to support massive workloads across globally distributed data centers. NoSQL databases use a variety of data models optimized for web, mobile, IoT, and analytics applications. I think their innovative approaches deliver higher throughput, lower latency, and dynamic scaling to handle fluctuating traffic. There are currently over 225 NoSQL database systems each with unique data models, consistency models, and capabilities. I think the diversity proves that rigid schemas could not effectively accommodate needs arising from public-facing services, cloud infrastructure, and connected devices entering the fray. From my personal experience, these are currently the 10 most popular and advanced NoSQL databases for scalable data storage.
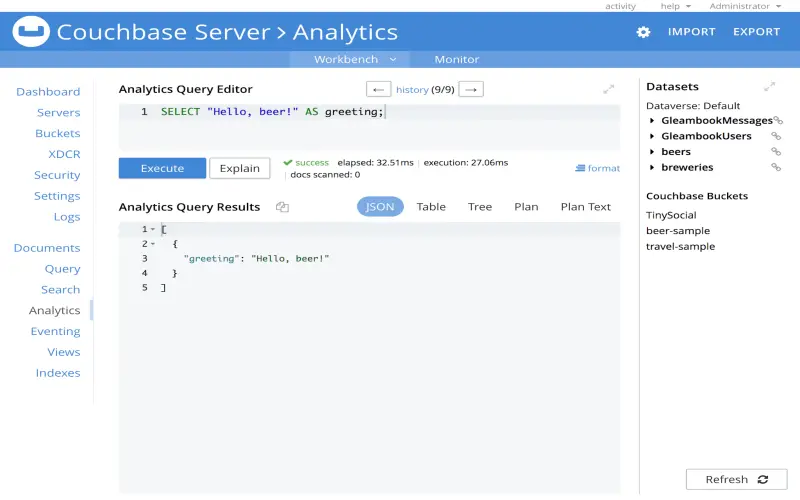
1. Couchbase Server
Couchbase provides an Engagement Database purpose-built for interactive web, mobile, and IoT applications. The flexible JSON data model with a fast key-value store and integrated search, analytics, and eventing makes it popular for modern applications. Couchbase scales linearly to handle high volumes on commodity hardware with a shared-nothing architecture. It replicates data across data centers for data locality and survivability. I find Couchbase performs well under load for low latency and high concurrency. The tunable consistency model ensures data accuracy despite distributed operations.
2. Astra DB
DataStax Astra DB delivers Apache Cassandra with a serverless operational model for developers. Just point your applications to the Astra DB cloud to leverage an elastic pay-per-use Cassandra cluster. Rich tooling cuts down dev cycles while auto-scaling, repairs, and security need no administration. High-performance Cassandra Query Language access remains consistent, even for global deployments. I think integrated caching boosts throughput over durable distributed storage. Role-based access controls secure production data safe from accidents. With discounts for dev/test usage, Astra DB lowers costs before production deployment.

3. Amazon DynamoDB
Fully managed AWS DynamoDB relieves developers from standing up distributed NoSQL infrastructure. The key-value and document database instantly scales table throughput while maintaining low-latency database access. From my personal experience, DynamoDB accommodates any volume of reads and writes with predictable performance. I find that adaptive capacity dynamically allocates throughput to match traffic levels using auto-scaling. Fine-grained access controls and encryption provide enterprise-grade security. Large DynamoDB tables span multiple partitions without impacting performance. High durability replicates data across AZs for disaster resilience.

4. MongoDB
One of the most popular document databases today, MongoDB operationalizes rich data models for modern applications. For web and mobile apps, the flexible JSON documents handle rapidly evolving data without migrations. MongoDB distributes and scales document shards across commodity servers for horizontal scale-out. Replica sets maintain redundant copies for high availability with tunable consistency. Indexing and aggregation deliver real-time analytics over live transactional data. The MongoDB Query Language provides expressive ways to filter, sort, and transform documents supporting complex use cases. Ops Manager and Atlas streamline operations for on-premises and multi-cloud deployments.
5. Redis
Redis delivers sub-millisecond performance for fast data access. The in-memory key-value cache scales linearly without dropping cache hit rates for low latency and high throughput. From my personal experience, Redis fits needs like real-time analytics, leaderboards, rate limiting and more than relational databases struggle to support. Redis use cases range from session caching, and pub/sub messaging to a transient highly available datastore. Redis Enterprise adds active-active clustering, instant scaling, flash memory storage, and conflict-free replicated databases for extreme memory caching at scale. Modules like RediSearch, RedisJSON, and RedisGraph extend capabilities while retaining Redis performance.

6. IBM Cloudant
Fully managed IBM Cloudant hosts a distributed Apache CouchDB database optimized for web and mobile applications. It scales document shards across data centers to accommodate heavy workloads. From my personal experience, multi-master replication syncs documents globally with tunable consistency and reduced conflicts. SDKs and APIs assimilate data changes from edge devices and apps enabling live dashboards. Advanced indexing and queries enable real-time analytics over continuously changing data. IBM Cloudant On-Prem allows private cloud deployment while connecting to public data sets. Fine-grained access controls secure sensitive information without introducing latency from external gateways. Monthly pricing simplifies cost planning without forcing capacity decisions.
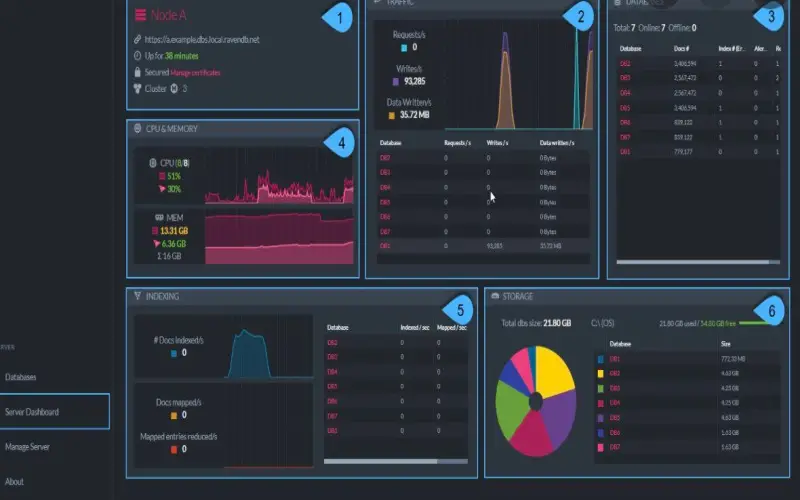
7. RavenDB
Modern applications demand a JSON document database delivering performance at scale. RavenDB is purpose-built to handle large volumes of reads and writes with low latency. Memory optimization and multi-core utilization translate into high throughput on commodity hardware. Dynamic sharding partitions data across clusters without downtime. From my personal experience, RavenDB compresses network traffic while avoiding distributed locking for faster transactions. Durable by default, data remains consistent despite failures. A unified SQL + NoSQL query framework interoperates across shared collections. Full-text search, aggregation, continuations, and changes feed enable real-time analytics over live data. RavenDB makes it easy to evolve schemas without migrations while ensuring ACID transactions.
8. Apache Cassandra
Netflix, Apple, and other internet giants rely on Apache Cassandra for their mission-critical applications at a massive scale. The highly available distributed database linearly scales writes across commodity servers with no single point of failure. Row-level masterless replication provides low-latency reads from the nearest replica. From my personal experience, Cassandra delivers continuous availability through operations like re-balancing without dropping client connections. A powerful data model defines rows and columns optimized for high query throughput across large data sets. Operational simplicity allows running large Cassandra clusters across multiple data centers. Commit log and mutable architecture durably persists writes before applying eventual writes for disaster recovery.
9. Apache HBase
Part of Apache Hadoop, HBase applications store structured records in tables optimized for random access at a petabyte scale. Underpinned by the HDFS distributed file system, HBase splits tables horizontally across nodes in a cluster. From my personal experience, strong row consistency simplifies app development without shard from the ground up. Fine-grained cell versioning automatically keeps multiple variants per record. This temporal dimension enables the reversal of writes and point-in-time queries without permanent deletes. HBase integrates with MapReduce for large-scale offline analytics across billions of rows and columns. Operational management aligns with existing Hadoop skill sets. Use cases like IoT, fintech, and healthcare take advantage of HBase storage for time series and sensor data.

10. Neo4j
A native graph database, Neo4j captures data relationships first with flexible schemas. With connections stored as first-class entities, graph algorithms traverse billions of edges across nodes at speed. From my personal experience, varied graph data models preserve molecular structures, fraud detection patterns, social networks, IT infrastructures, and more at the enterprise scale.








")






{kind=link}