
Voice and speech recognition technology enables machines to interpret human speech. This can power voice assistants, transcribe audio, analyze sentiment, and more. Python’s extensive machine-learning libraries make it a popular choice for building voice and speech applications. From recording audio to extracting features, training models, and synthesizing speech – these libraries help developers utilize Python’s strengths for speech processing. Whether looking to simply transcribe some audio files or develop an enterprise-level voice assistant, these Python libraries can provide the foundation. I believe that these 10 Python libraries stand out for developing robust voice and speech recognition capabilities.
1. SpeechRecognition
The SpeechRecognition library provides a Python interface for several popular speech recognition engines. This includes Google Speech Recognition, Wit.ai, IBM Speech to Text, and Sphinx, among others. With just a few lines of code, you can start transcribing audio from microphones, files, or streams. SpeechRecognition handles the interaction with the speech recognition services. This simplifies your code. You don’t have to know the unique APIs for each platform. The library also has nice features like passing timeouts and phrase hints to optimize transcription accuracy. From my perspective, SpeechRecognition is likely the easiest way to get started with adding speech recognition to a Python project.
2. Pyttsx3
While the previous libraries focus on transcribing speech, pyttsx3 provides text-to-speech capabilities. It converts text into synthetic speech audio streams. Pyttsx3 uses native speech engines on Windows and MacOS systems. The library has a straightforward API for converting text to speech. You can control properties like volume, rate, voice, output file, etc. Pyttsx3 provides an uncomplicated way to add text-to-speech functionality alongside speech recognition in an application. This enables text input systems to also speak their responses.

3. PyAudio
To interpret speech, an application first needs to record and digitize the audio. PyAudio provides bindings to PortAudio, a cross-platform audio input/output library. With PyAudio you can effortlessly manage audio streams from microphones or speakers in Python. It decouples the complexities of handling audio streams across different platforms. PyAudio plays perfectly with speech recognition libraries like SpeechRecognition. It makes it simple to pipe microphone audio into SpeechRecognition for transcription.

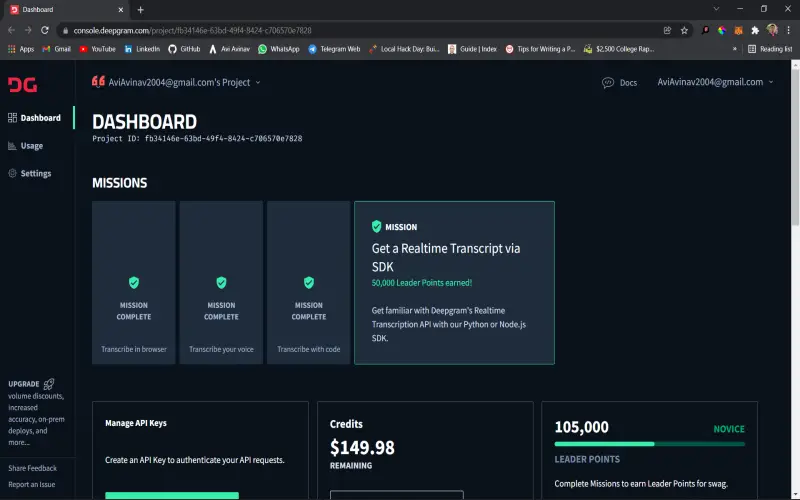
4. Deepgram
Deepgram is an accurate commercial speech recognition platform. They offer a Python SDK for interfacing with their API. The Deepgram library streams audio to its cloud API and returns quick transcriptions. It has methods for transcribing live audio, uploading audio files, and retrieving results. Deepgram promotes its “Human Parity” speech recognition engine. It reportedly has equal or better accuracy than human transcription in some tests. Their API also returns confidence scores at the word and sentence levels. This allows for assessing the certainty of results. The Deepgram Python SDK provides a straightforward way to leverage its cutting-edge speech recognition service.
5. Librosa
Librosa is a popular Python library used for music and audio analysis. It has great support for speech processing tasks like Voice Activity Detection (VAD). VAD can automatically detect speech in an audio stream and extract the spoken parts. This is important for voice recognition applications. Librosa has tools to analyze raw audio signals. This can help enrich transcriptions with additional acoustic details about tone, pacing, etc. It also has audio feature extraction capabilities. These audio fingerprints can train machine learning models to categorize speakers, languages, emotions, and other attributes from voice recordings alone. Librosa brings research-grade speech-processing capabilities to Python.

6. Pysptk
Pysptk wraps the Speech Toolkit (SPTK) in Python. SPTK contains common speech analysis algorithms focused on Statistical Parametric Speech Synthesis. This includes low-level acoustic feature extraction from audio like Mel-Frequency Cepstrum Coefficients (MFCCs). MFCCs compactly represent the voice characteristics of a signal. They are one of the most used audio features in speech recognition systems. Pysptk makes it easy to leverage SPTK’s algorithms for generating descriptive audio features from voice data in Python machine-learning applications.

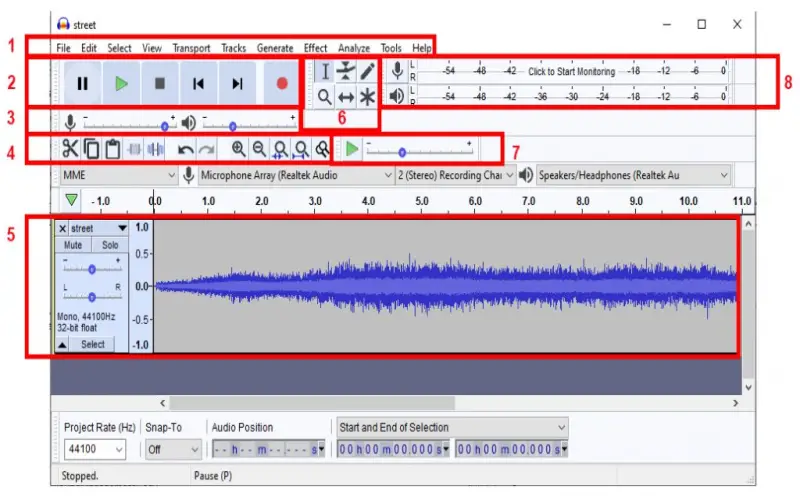
7. Audacity
While not technically a Python library, Audacity deserves a mention. Audacity is an easy-to-use open-source audio editing app. It provides an intuitive graphical interface for recording, cleaning, transforming, and analyzing audio. Audacity can help preprocess large volumes of speech data to prepare it for training speech recognition systems. Operations like noise removal, trimming, format converting, and more can be batch-processed across many audio files. This helps create higher quality, consistent training data from real-world voice recordings. The resulting cleaned datasets will produce more accurate speech recognition models.
8. Speechbrain
SpeechBrain provides an all-in-one open-source speech toolkit implemented in Python and PyTorch. It has modules for tasks across the speech processing pipeline. This includes audio data loading, feature extraction, model building, and more. SpeechBrain implements many state-of-the-art speech recognition techniques like CTC, RNN-Transducers, and Transformer models. It makes it easy to leverage the latest speech research innovations without in-depth knowledge of speech signal processing. SpeechBrain provides full-functioning speech recognition examples to build off of. This high-level toolkit accelerates the development of custom speech recognition models in Python.

9. Parselmouth
Parselmouth provides Python bindings to the Praat phonetic analysis library. It grants access to Praat’s suite of speech analysis capabilities directly within Python. This includes tools like vowel detection, intensity measurements, fundamental frequency estimation, and more. Parselmouth makes it straightforward to extract detailed phonetic attributes from voice recordings with Praat’s longstanding algorithms. The extracted audio features can then be used to train custom speech, recognition models.
10. Google Speech Engine
Google provides its own Speech Recognition Python library. It interfaces directly with Google Cloud’s Speech-to-Text API. The library handles audio streaming, transmission of data to Google’s servers, and returning transcriptions. It provides simple access to Google’s powerful speech recognition engine from Python code. The library also supports speaker diarization. This can automatically detect distinct speakers from multi-person audio. Google’s offerings provide industrial-strength speech-to-text functionality through this handy Python wrapper.









")






{kind=link}