
Web scraping is type of a PC tool that allows us to fetch data from websites. It works via sending a message to an internet website and retrieving back plain HTML code, so we can extract the required information from it. Once we have the information, we clean the data and set them up for easy use. This process is helpful as it saves us from doing the hard work of collecting data manually. Plus, it can also help us gather data which is hard to gather manually. We can use web scraping to learn about critical information from the textual content, photos, and videos observed on the internet for product descriptions, customer remarks, or maybe photos or movies. We also can extract information like product costs, stock popularity, or contact info from tables and lists on websites. Let’s start your web scraping process by exploring the Top 10 Python Libraries for Web Scraping and Data Extraction.
1. Beautiful Soup
Beautiful Soup is a Python library that serves for extracting data from HTML and XML documents, in particular for website scraping. It structurally organizes web page source code, and process data extraction. It was created by Leonard Richardson and supported by using Tide Lift. It is highly compatible with Python 3 and Python 2.4. This library simplifies data retrieval by using methods and easy Python commands, manages information encoding, and collaborates with extensively used Python parsers like LXML and HTML, by taking into account parsing strategies.

2. Scrapy
Scrapy is a bit slow and open source web scraping framework written in Python, initially designed for web scraping, but it is also used for data extraction using APIs. It was created in Cambuslang and is currently maintained by using Zyte (previously Scraping Hub), a web scraping development company. Scrapy’s architecture revolves around spiders, which are self-contained crawlers with unique instructions. This approach is much like the do not repeat your self-principle in frameworks like Django, it makes it great for building and expanding huge crawling systems by permitting builders to reuse their code.

3. Requests
The Requests library in Python is used for sending HTTP requests to a specific web address and receiving the response. It gives integrated techniques for making special types of requests like GET, POST, PUT, PATCH, HEAD, and more. When you send an HTTP request it’s either to fetch data from the internet or send data to a server. It’s like a conversation between a customer and a server. In this case, we use GET request, which is used to get data from a web server of a specific website. Using Python’s Requests library we can without any difficulty manage both the request you send and the response you receive.

4. Selenium
Selenium is a widely used open-source tool for automating tests of web user interfaces (UI). It was created by Jason Huggins in 2004, and it was further developed by Thought Works. Selenium is flexible and compatible with various internet browsers, operating systems like Windows, Linux, Solaris, and Macintosh, and even cellular platforms including iOS, Windows Mobile, and Android. It works well on several programming languages like C#, Java, Perl, PHP, Python, and Ruby, and also language drivers. Currently, Selenium Web driver is most famous with Java and C#.

5. Lxml
So, Lxml is a Python library that is used for working with XML and HTML documents as well as for web scraping. There are many existing XML parsers available in the market but in most cases, developers need to create their custom parsers for higher efficiency and specific use cases. And this is why Lxml is famous. It stands out for its user-friendly API, great speed in parsing massive files, plenty of documentation, and the potential to easily convert data into Python datatypes making file manipulation easier.

6. Html5lib
Html5lib is another great Python library that applies the HTML5 parsing rules carefully to how modern-day browsers parse HTML data. This makes sure that we receive the same parsed HTML text as we see in the browser. Html5lib is also incredible at repairing damaged HTML and adding lacking tags to make the textual content seem like proper HTML data. It’s widely recognized because it can manage various types of HTML content and tags. But, Html5lib is a bit slow because it is created mostly by using Python code which is also slow.

7. Mechanical Soup
Mechanical Soup is another Python package that deals with cookies, follows redirects and can navigate hyperlinks and bureaucracy on webpages mechanically. It was created by M Hickford, using the Mechanize library. It was later maintained via Kovid Goyal in 2017. It offers functions like beginning URLs, filling HTML forms, understanding robots.txt files, handling HTTP-Equiv, and browser strategies like.Returned() and .Reload(). MechanicalSoup simplifies internet browsing responsibilities by automating these moves.

8. Auto Scraper
Now, we have reached Auto Scraper which is also a Python web scraping library designed to make web scraping smart, automated, rapid, and easy to use. It’s a very lightweight library and will not slow down your computer. You can use it for data scraping without any difficulty thanks to its user-friendly interface. You simply have to write a few lines of code and volha. All you need to do is input the URL or the HTML content of the website which you want to scrape data from with a list of sample data you need to extract.

9. Pyspider
This is a robust web crawling system in Python created with a consumer-friendly user interface that consists of a script editor, challenge reveal, mission manager, and result viewer. It can connect to more than one database like MySQL, MongoDB, Redis, SQLite, Elasticsearch, and PostgreSQL with SQLAlchemy using its backend. This also utilizes message queues, which include RabbitMQ, Beanstalk, Redis, and Kombu. It gives features like project priority, retries, periodic duties, recrawling based totally on statistics age, and more.

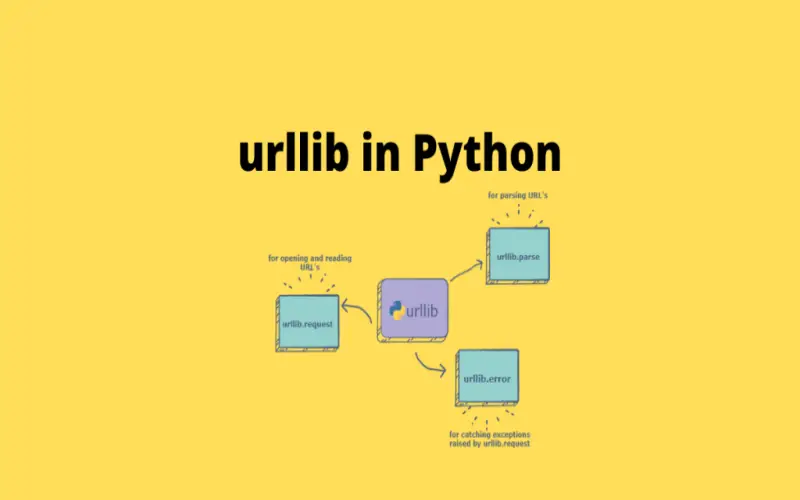
10. Urllib
Last but not least, there’s “Urllib.” Which you must have heard of. It helps you retrieve data from URLs, and it comes with different modules to handle all sorts of URL-related tasks. You can use urllib.Request for opening and reading URLs, urllib.Parse for parsing URLs, urllib.Error for handling exceptions, and urllib.Robotparser for parsing robot.txt files. It’s a flexible tool for doing URL-related stuff in Python. It’s also used in several well-known backend libraries.




 Prevention Strategies In DHCP Networks")










{kind=link}