
Deep learning is commonly utilized in scientific computing to address challenging issues. For example, machine learning algorithms can help computers play chess, get more innovative, and perform surgery in an automated future. AI and machine learning are modern industry’s underpinnings. Machine learning has made businesses more competent and more efficient. Industry experts and IT heavyweights watch deep learning as the computing paradigm shifts. Deep learning technology is used globally and is powered by AI. Deep learning trends anticipated by experts have reduced error rates and enhanced network performance for a specific activity. This article lists 2023’s top deep learning forecasts and trends. Deep learning algorithms employ neural networks to complete tasks. This article lists Ten deep learning algorithms and explains how to mimic the human brain using artificial neural networks.
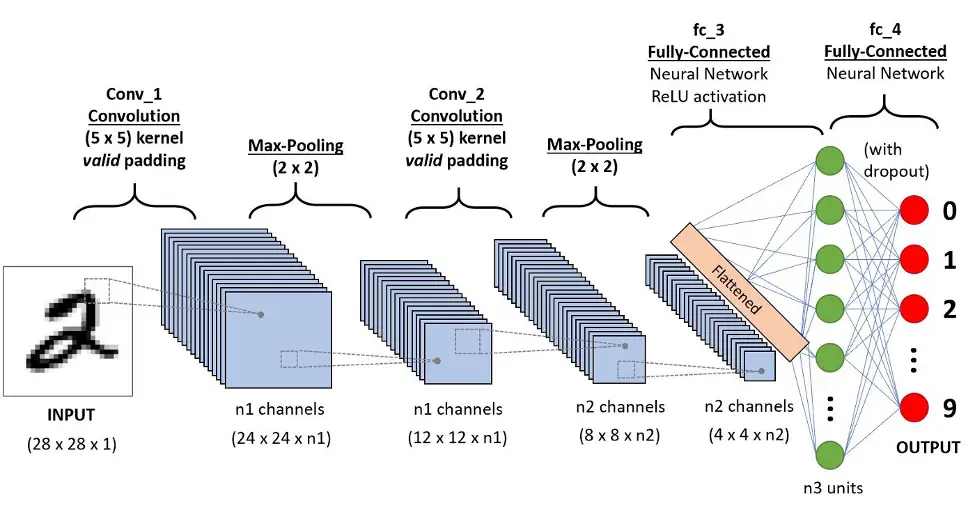
1. Convolutional Neural Networks (CNNs)
- CNN, called ConvNets, are used for image processing and object detection. Yann LeCun founded CNN as LeNet in 1988 and recognized ZIP codes and numbers.
- CNN recognizes satellite photos, analyzes medical imaging, forecasts time series, and detects anomalies.
- CNN’s layers process and extract data features.
Convolution:
- CNN’s convolution layer uses many filters.
- Linear Rectified (ReLU)
- CNN’s ReLU layer performs element operations. Rectified feature map is the outcome.
Layer-Pooling:
- A pooling layer receives the rectified feature map. Pooling minimizes the feature map’s size.
- The pooling layer does flatten the pooled feature map’s two-dimensional arrays.
Full Layer:
- The flattened pooling matrix produces a fully connected layer that classifies and identifies pictures.
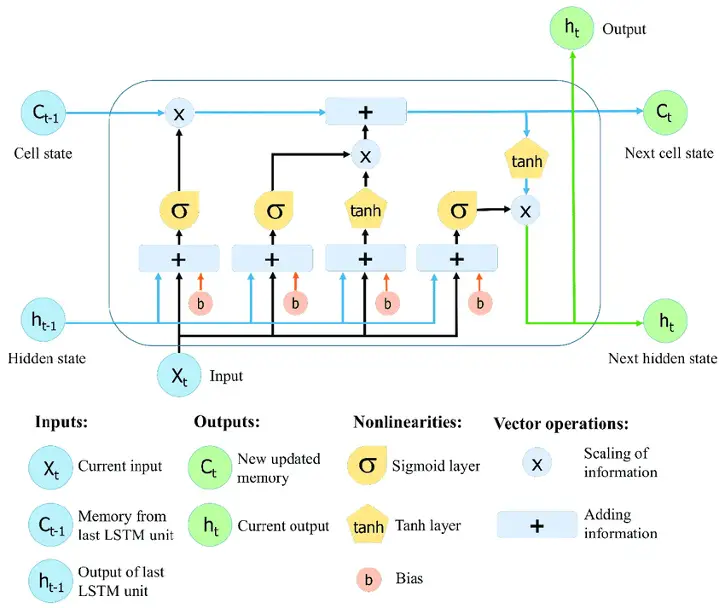
2. Long Short-Term Memory Networks (LSTMs)
- LSTMs are RNNs that learn and memorize long-term dependencies. Long-term memory is typical.
- LSTMs store data. They remember past inputs, which helps in time-series prediction. LSTMs are chain-like structures with four interacting layers. LSTMs are utilized for speech recognition, music composition, and drug development.
- First, they forget the past.
- They update cell-state values selectively next.
- Lastly, the cell output.
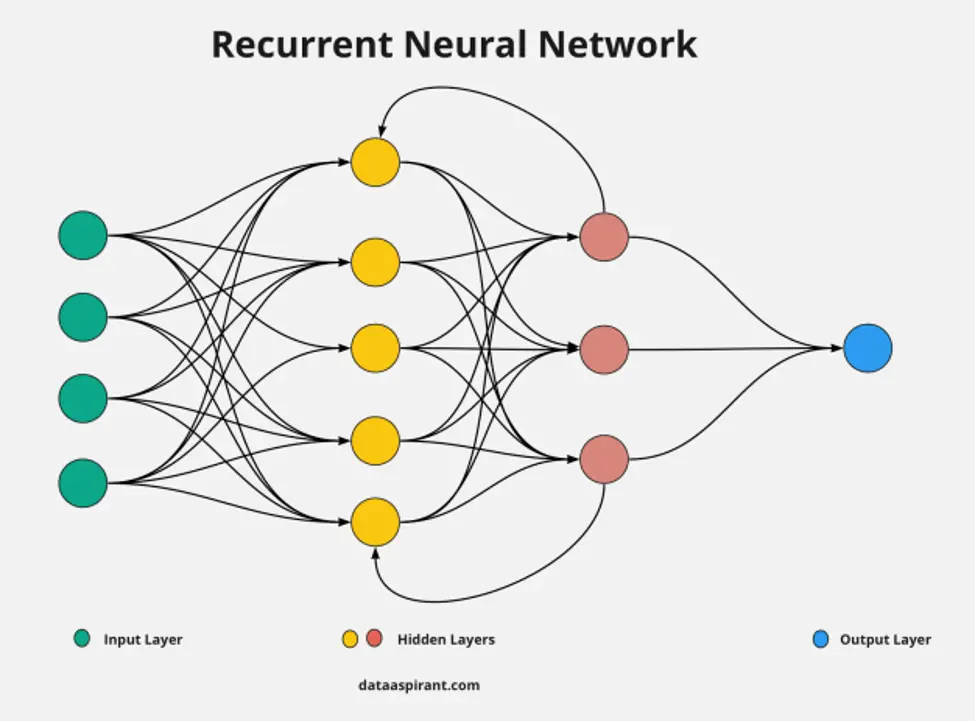
3. Recurrent Neural Networks (RNNs)
CNN’s directed cycles allow LSTM outputs to be fed into the current phase. LSTM output becomes current phase input, and its internal memory remembers prior inputs. Image captioning, time-series analysis, natural language processing, handwriting recognition, and machine translation use RNNs.
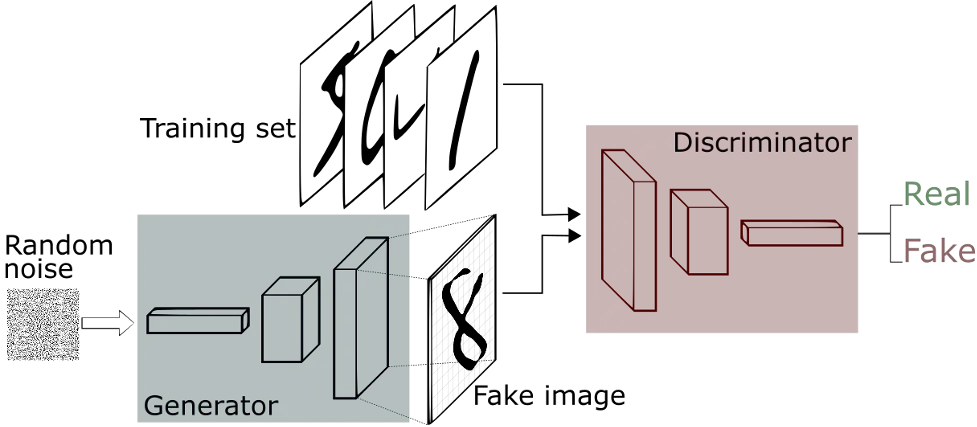
4. Generative Adversarial Networks (GANs):
- GANs create new data instances that resemble training data. For example, a generator learns to generate bogus data, and a discriminator learns from it.
- GAN use has grown. Improve astronomical photos and replicate gravitational lensing for dark-matter studies. GANs recreate low-resolution, 2D textures in ancient games at 4K or higher quality.
- GANs create realistic images, cartoon figures, and 3D objects.
- The discriminator learns to identify phony from actual sample data.
- The generator provides phony data during initial training and the discriminator learns to spot it.
- GAN provides model updates to the generator and discriminator.
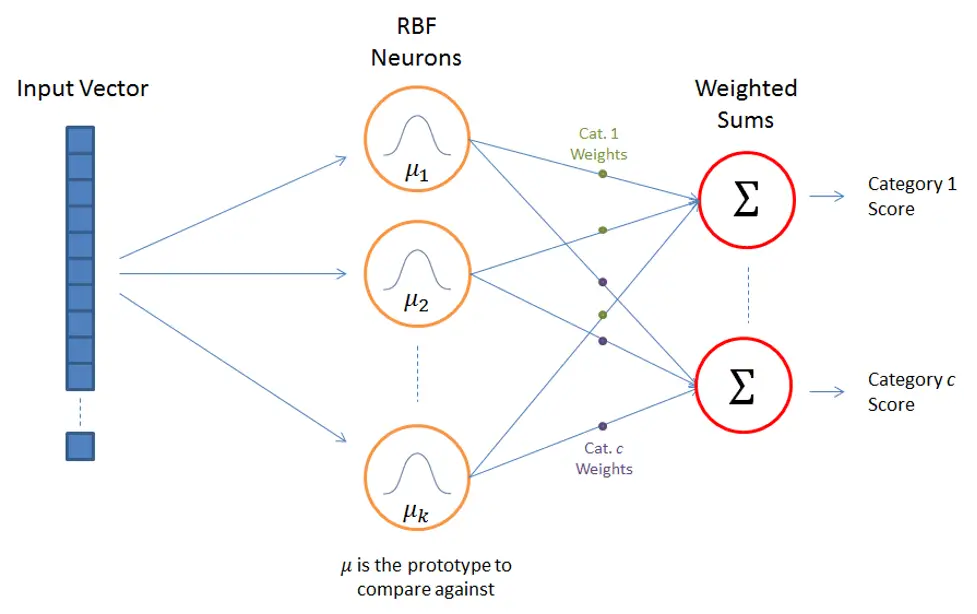
5. Radial Basis Function Networks (RBFNs)
RBFNs use radial basis functions as activation functions. These layers are used for categorization, regression, and time-series prediction.
- RBFNs classify by comparing inputs to training set examples.
- RBFNs have a layer input vector, and RBF neurons are present.
- The output layer has one node per data category or class.
- Hidden-layer neurons have Gaussian transfer functions with outputs inversely proportional to neuron distance.
- Output is a linear mixture of input radial-basis functions and neuron parameters.
6. Multilayer Perceptrons (MLPs)
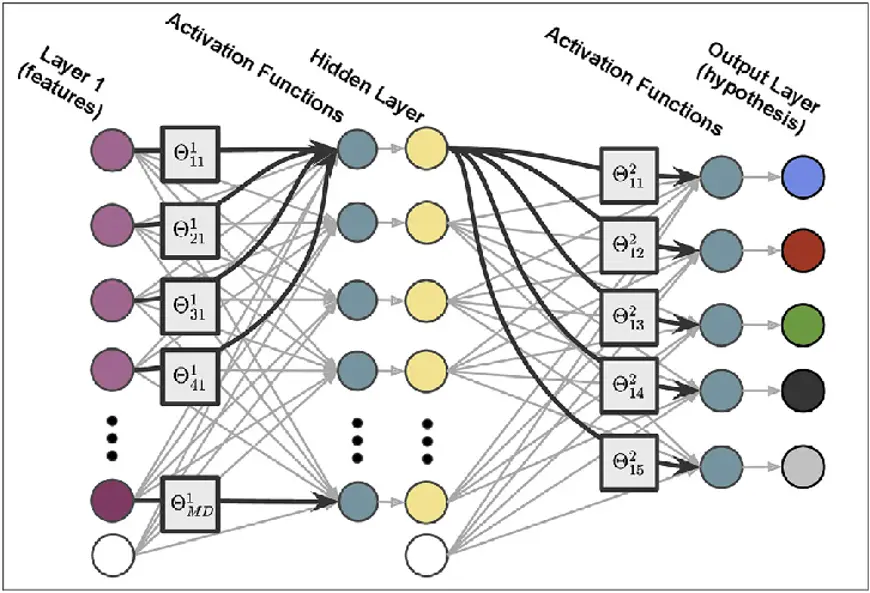
- MLPs are feedforward neural networks with activation-function perceptrons. MLPs have fully-connected input and output layers. They contain the same input and output layers but may include hidden layers and can be used to develop speech-, image-, and machine-translation software.
- MLPs feed network inputs. Neurons link in a graph, so signals travel in one direction.
- MLPs compute input with input layer and hidden layer weights.
- MLPs use activation functions to fire nodes, ReLUs, and sigmoid functions and then activate.
- MLPs train the model to understand correlations and dependencies using a training data set.
- MLP example:Cat and dog photos are classified using weights, bias, and activation functions.
7. Self-Organizing Maps (SOMs)
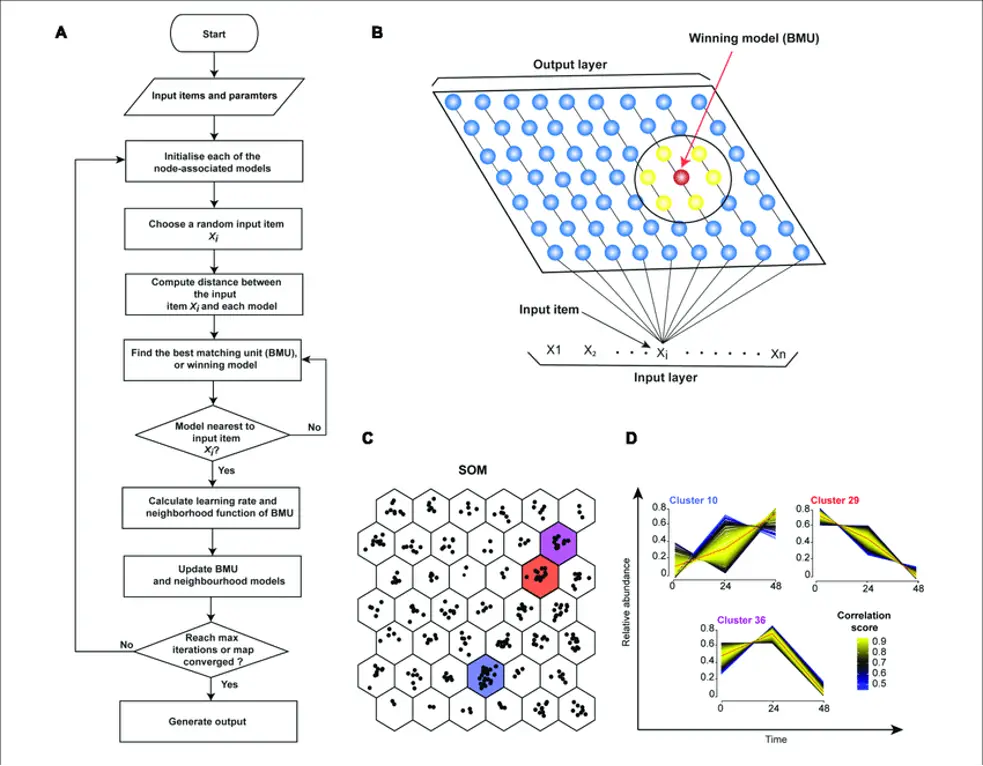
- Teuvo Kohonen devised SOMs, which minimize data dimensionality through self-organizing neural networks.
- Data visualization helps humans visualize high-dimensional data. SOMs assist users in comprehending high-dimensional data.
- SOMs choose a random training vector to initialize each node’s weight.
- SOMs check each node for the most likely input vector weights. BMU is the winning node (BMU).
- The number of BMU neighbors decreases when SOMs discover them.
- Sample vectors win in SOMs. A node’s weight varies as it approaches a BMU.
- Further from the BMU, the neighbor learns less; Step 2 is repeated N times.
8. Deep Belief Networks (DBNs)
- DBNs are generative models with numerous layers of stochastic, latent variables. Hidden units are binary latent variables.
- Each RBM layer in a DBN communicates with the preceding and subsequent layers. Deep Belief Networks (DBNs) recognize images, videos, and motion.
- Greedy algorithms train DBNs, and learning learns top-down generating weights layer-by-layer.
- DBNs sample the top two hidden layers using Gibbs. This level samples RBM’s top two hidden layers.
- DBNs sample visible units are utilizing a single run of ancestral sampling over the model.
- DBNs learn that a single, bottom-up pass may infer latent variable values in every layer.
9. Restricted Boltzmann Machines (RBMs)
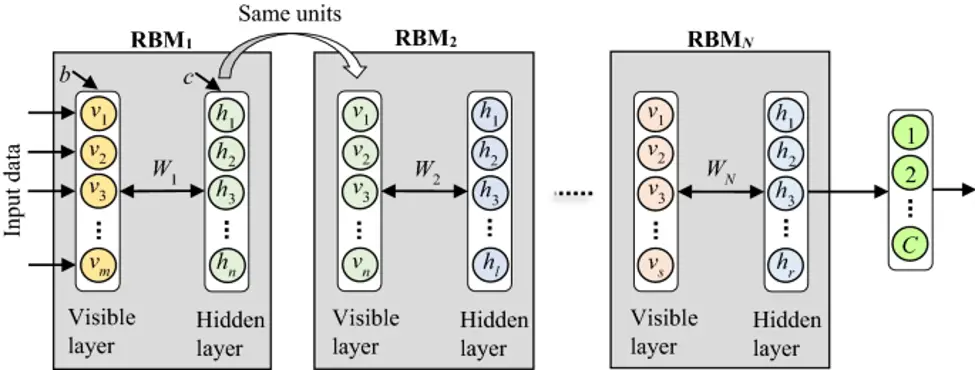
RBMs were created by Geoffrey Hinton and can learn from a probability distribution over inputs. Deep learning algorithms reduce dimensionality, classify, predict, filter, learn features, and model topics. RBMs form DBNs.
RBMs are double-layered.
- Units visible
- Units hidden
- Every visible unit connects to every remote unit. RBMs have no output nodes and a bias unit coupled to all visible and hidden units.
- RBMs pass forward and backward.
- RBMs, translate inputs into numbers in the forward pass.
- RBMs weight each input and add a bias; output goes to the buried layer.
- In the backward pass, RBMs translate those numbers into reconstructed inputs.
- RBMs integrate each activation with individual weight and general bias to recreate the visible layer.
- The RBM compares the reconstruction to the original input at the visible layer.
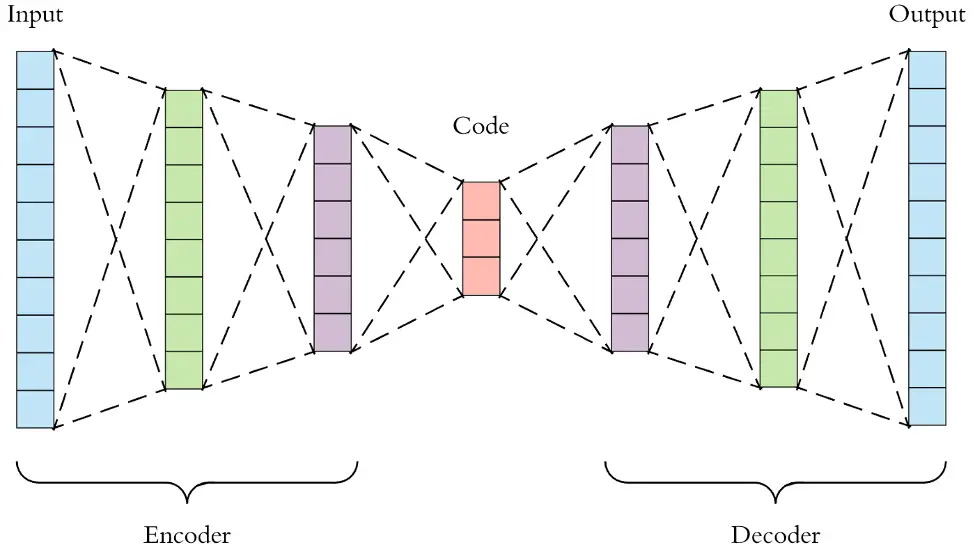
10. Autoencoders
In autoencoders, input and output are the same. Geoffrey Hinton created autoencoders in the 1980s for unsupervised learning. They’re trained neural networks that duplicate input-to-output data. Pharmaceutical discovery, popularity prediction, and image processing using autoencoders.
- Encoder, code, and decoder make up an autoencoder.
- Autoencoders change input into another representation and try to reconstruct the original information.
- Unclear digit images are sent to an autoencoder neural network.
- Autoencoders encode images and minimize their size.
- The autoencoder then reconstructs the image.








")






{kind=link}